Ultimamente si fa un gran parlare di questi Large Language Models, anche se molte volte non ce ne rendiamo neanche conto. Strumenti come Chat GPT-3, e altre applicazioni AI si basano proprio su questi modelli e stanno entrando sempre di più nelle nostre vite. E’ quindi importante approfondire questo tipo di concetto e comprendere in che cosa consistono, come sono strutturati e come funzionano. In questo articolo vedremo, cerchiamo di dare una panoramica su questo argomento. Per chi volesse poi approfondire, suggeriamo di visitare altri articoli più dettagliati in merito.
Che cosa sono i Large Language Models
I Large Language Models (LLM) sono modelli di intelligenza artificiale che hanno dimostrato notevoli capacità nel campo del linguaggio naturale. Si basano principalmente su architetture complesse che consentono loro di catturare le relazioni linguistiche nei testi in modo efficace. Questi modelli sono noti per le loro dimensioni enormi (da qui appunto il termine “Large“), con milioni o miliardi di parametri, che consentono loro di memorizzare una vasta conoscenza linguistica e di adattarsi a una varietà di compiti.
In sintesi, questi modelli di intelligenza artificiale basati su reti neurali trasformer, addestrati su grandi quantità di testi per apprendere la struttura e il significato del linguaggio naturale. Utilizzano il meccanismo di autoattenzione per catturare le relazioni tra le parole e sono capaci di generare e comprendere il testo in modo contestuale.
Che cosa sono le reti neurali Transformer
Una rete neurale Transformer è una particolare architettura di reti neurali artificiale che è stata introdotta nel 2017 da Vaswani et al. con l’articolo “Attention Is All You Need“. È diventata una delle architetture più influenti e ampiamente utilizzate nel campo del linguaggio naturale e dell’apprendimento automatico.
L’architettura Transformer è caratterizzata da due aspetti chiave:
- Meccanismo di auto-attenzione: La caratteristica distintiva dei Transformer è il meccanismo di auto-attenzione, che consente al modello di assegnare pesi differenti alle parole in una sequenza a seconda del loro contesto. Questo meccanismo permette di catturare le relazioni tra le parole in modo efficiente e di gestire dipendenze a lungo raggio all’interno del testo. In breve, la rete può “prestare attenzione” a parti specifiche del testo in modo adattivo.
- Strutture senza ricorrenza: A differenza delle reti neurali ricorrenti (RNN), che trattano le sequenze di dati in modo sequenziale, le reti Transformer lavorano in modo altamente parallelo. Ciò significa che possono elaborare l’input in modo più efficiente e scalabile, il che ha reso possibile addestrare modelli con molti parametri.

Quindi l’architettura Transformer è costituita da più strati, o blocchi simili che possono essere impilati uno sopra l’altro. Ogni blocco contiene più sotto-moduli, tra cui:
- Multi-Head Self-Attention: Questo modulo calcola l’autoattenzione su una sequenza di input, consentendo al modello di assegnare pesi diversi a ciascuna parola in base al contesto.
- Feed Forward: Questi strati di reti neurali Feed Forward vengono inseriti per elaborare i dati dell’auto-attenzione e produrre rappresentazioni intermedie.
- Add & Norm: questi strati vengono utilizzati per stabilizzare il processo di apprendimento.
- Connessioni residue: Ogni blocco contiene connessioni residue per facilitare la propagazione del gradiente durante l’addestramento.
Le reti Transformer possono essere utilizzate in diverse configurazioni, tra cui l’encoder-decoder per la traduzione automatica, l’encoder singolo per il riconoscimento di entità o il solo decoder per la generazione di testo. Questa architettura è altamente adattabile e flessibile, ed è stata alla base di molti dei Large Language Models (LLM) di successo che sono emersi negli ultimi anni, come BERT, GPT-3 e altri.
Come funzionano i Large Language Models
Quando si pone una domanda a un Large Language Model (LLM) tramite una chat, il modello segue un processo di comprensione della domanda e successivamente genererà una risposta in modo da fornire una conversazione coerente e significativa.
Il processo inizia con l’analisi della domanda da parte del modello. Questo implica la suddivisione della domanda in unità più piccole chiamate “token” (tokenizzazione del testo immesso), come parole o sottoinsiemi di parole, per renderla più gestibile. In seguito, il modello cerca di capire il significato della domanda, identificando parole chiave, dipendenze tra le parole e il contesto in cui la domanda è posta. Questa fase di intendimento è cruciale per capire ciò che l’utente sta cercando di ottenere.
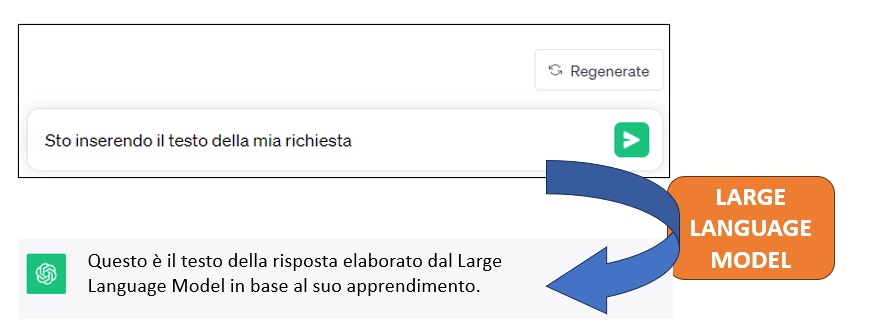
Una volta che il modello ha compreso la domanda, passa alla generazione della risposta. Utilizzando le informazioni acquisite durante l’addestramento su grandi quantità di testi, il modello genera una risposta che sia coerente e informativa in relazione alla domanda posta. Questa risposta può variare in base alla complessità della domanda, alla specificità del contesto e alla conoscenza accumulata dal modello.
In alcune situazioni, il modello potrebbe generare più di una possibile risposta e quindi selezionare quella che ritiene più adeguata in base a criteri come la coerenza, la pertinenza e l’accuratezza. Questo processo consente al modello di adattare le sue risposte alle esigenze specifiche dell’utente.
Infine, il modello restituisce la risposta finale all’utente tramite la chat o l’interfaccia in uso. Tuttavia, è importante notare che la qualità delle risposte può variare a seconda della comprensione del modello e delle informazioni a sua disposizione. Inoltre, i LLM non hanno una comprensione intrinseca del mondo e basano le loro risposte sui dati di addestramento, il che significa che potrebbero non sempre essere aggiornati o riflettere gli sviluppi più recenti.
Le fasi di sviluppo di un Large Language Model
Lo sviluppo di un Large Language Model (LLM) è un processo complesso e richiede una serie di step chiave. Ecco una panoramica degli step tipici coinvolti nello sviluppo di un LLM:

- Raccolta e preparazione dei dati: Il primo passo consiste nella raccolta di una vasta quantità di testi in lingua naturale da varie fonti, come libri, articoli, siti web, social media e altro. Questi dati serviranno da corpus di addestramento per il modello. È importante pulire e preparare i dati, rimuovendo dati indesiderati o rumorosi e standardizzando il formato. I dati raccolti devono essere “tokenizzati” e suddivisi in unità più piccole, come parole o sottoinsiemi di parole (token). Inoltre, è comune applicare tecniche di normalizzazione, rimuovere la punteggiatura e gestire le maiuscole/minuscole.
- Progettazione dell’architettura: La progettazione dell’architettura del modello è un passo cruciale. È necessario decidere la dimensione del modello (cioè il numero di parametri), la profondità della rete e altri dettagli architetturali. L’architettura del trasformer è spesso utilizzata come base.
- Addestramento del modello: Questo è uno dei passaggi più intensivi in termini di risorse. Il modello viene addestrato sul corpus di dati preparato. Durante l’addestramento, il modello cerca di prevedere le parole o le frasi successive nei testi. L’addestramento può richiedere molto tempo e potenza di calcolo, e spesso viene eseguito su cluster di server ad alta potenza.
- Ottimizzazione e tuning: Una volta addestrato, il modello può essere sottoposto a diverse fasi di ottimizzazione per migliorare le prestazioni. Questo può includere l’aggiustamento degli iperparametri, il fine-tuning su compiti specifici e l’ottimizzazione dell’architettura stessa.
- Valutazione delle prestazioni: È importante valutare le prestazioni del modello su una serie di metriche pertinenti per il compito specifico. Questo aiuta a determinare quanto bene il modello svolge il compito e a identificare eventuali aree di miglioramento.
- Implementazione e integrazione: Una volta che il modello ha raggiunto le prestazioni desiderate, può essere implementato e integrato in un’applicazione o un sistema. Ciò può richiedere l’ottimizzazione per l’efficienza e la scalabilità.
- Validazione etica e legale: È importante considerare le implicazioni etiche e legali dell’uso del modello, come la privacy dei dati, il contenuto generato, la discriminazione e altri aspetti etici e normativi.
- Monitoraggio e manutenzione: Dopo l’implementazione, il modello richiede monitoraggio continuo per garantire che le sue prestazioni siano stabili e che non emergano problemi imprevisti.
- Aggiornamenti e miglioramenti: I modelli di lingua possono beneficiare degli aggiornamenti successivi, sia per adattarsi a nuovi dati che per migliorare le prestazioni. È importante continuare a sviluppare e migliorare il modello nel tempo.
Questi step rappresentano una panoramica generale del processo di sviluppo di un Large Language Model. Ogni fase richiede competenze e risorse significative, e il successo del modello dipenderà dalla qualità dei dati, dall’architettura, dall’addestramento e dalla validazione.
Alcuni dei Large Language Models più noti
Eccovi alcuni esempi dei LLM più noti e ampiamente utilizzati. Ci sono molte altre varianti e modelli specializzati che vengono sviluppati costantemente per affrontare specifici compiti legati al linguaggio naturale. Ogni modello ha le proprie caratteristiche e vantaggi, e la scelta del modello dipende spesso dalle esigenze specifiche dell’applicazione.
- GPT-3 (Generative Pre-trained Transformer 3): GPT-3 è uno dei LLM più noti e avanzati. Sviluppato da OpenAI, è composto da 175 miliardi di parametri ed è noto per la sua capacità di generare testo coerente e di qualità su una vasta gamma di compiti legati al linguaggio.
- BERT (Bidirectional Encoder Representations from Transformers): BERT, sviluppato da Google, è noto per la sua capacità di comprensione del contesto e l’elaborazione bidirezionale del testo. Si è dimostrato efficace in compiti come il riconoscimento delle entità, il completamento delle frasi e l’analisi del sentiment.
- T5 (Text-to-Text Transfer Transformer): T5 è un altro modello di trasformer sviluppato da Google che adotta un approccio “testo-a-testo”, trattando sia i dati di input che quelli di output come sequenze di testo. Questo modello è altamente flessibile e può essere utilizzato per una vasta gamma di compiti, come la traduzione automatica e la generazione di testo.
- RoBERTa (A Robustly Optimized BERT Pretraining Approach): RoBERTa è una variante di BERT sviluppata da Facebook AI Research (FAIR) che si concentra sull’ottimizzazione dell’addestramento pre-dimensionamento. Ha dimostrato prestazioni superiori in una serie di compiti di linguaggio.
- XLNet: XLNet è un altro modello basato su trasformer sviluppato da Google Brain e Carnegie Mellon University. Si basa su una variante di preallenamento che tiene conto di tutte le permutazioni possibili delle parole in una frase. Questo approccio migliora la comprensione del contesto e la generazione di testo coerente.
- Turing-NLG: Turing-NLG è un LLM sviluppato da Microsoft ed è noto per le sue prestazioni eccezionali nella generazione di testi in linguaggio naturale. È stato utilizzato in applicazioni di chatbot e generazione di contenuti.
- DistilBERT: DistilBERT è una versione più leggera e più veloce di BERT sviluppata da Hugging Face. Sebbene abbia meno parametri rispetto a BERT, mantiene prestazioni decenti in una varietà di compiti di linguaggio.
Alcune applicazioni dei Large Language Models
i Large Language Models (LLM) hanno trovato applicazioni in una vasta gamma di settori e compiti legati al linguaggio naturale. Di seguito sono elencate alcune delle applicazioni più importanti e rilevanti:
- Traduzione automatica
- Generazione di testo
- Chatbot e assistente clienti virtuali
- Analisi del sentiment
- Correzione grammaticale
- Ricerca e analisi dei testi (insights, riassunti, ecc..)
- Generazione automatica di codice sorgente
- Educazione (tutor virtuali, strumenti di apprendimento automatico e materiali didattici personalizzati).
- Creazione di contenuti multimediali (descrizioni di immagini e video, sottotitoli, script audio e molto altro).
- Creazione di risposte automatizzate all’assistenza clienti
Queste sono solo alcune delle numerose applicazioni dei Large Language Models, e l’uso di queste tecnologie continua a espandersi in una vasta gamma di settori.