Introduction
Are you a developer and have you always wished to be able to implement code in parallel and try it on a cluster of processors? Well, now you can do it, cheaply and easily at your home. Thanks to the low cost of the Raspberry Pi boards, now you can realize a small cluster on which to practice and become familiar with parallel programming.
In this article, you’ll see how easy it is to make a small cluster consisting of two Raspberry Pi boars. As a programming language you will use Python and as for programming in parallel, you will see how easy you can be implemented parallel code thanks to the MPI library. A series of examples will then introduce you to the basic concepts of the parallel programming that will be useful for you to develop any project.
Parallel Programming
So far, very probably, you have always seen the code as a sequence of commands that are executed one after another, in serial mode, and for serial it is not intended from the beginning to the end of the code, but a command at a time consecutively. So when you implement the code to solve a problem or in general to carry out a specific task, you desing a code in this way eventually creating what is generally called a serial algorithm.
Actually this is not the only way to design algorithms. When you have to do with systems working in parallel then you must begin to think differently, and that is precisely here that the Parallel Programming comes. In fact, when you deal with parallel computing you must begin to think the things working differently. In fact, when you are developing code, you will need to start thinking if some portion is more efficient if it is calculated in parallel, that is, by multiple systems simultaneously, or whether it is better they calculate it serially. In the end the result of this will be a parallel algorithm.
Thus while the code is developed, it will be your task to think about what commands can be distributed among multiple systems, in what way and how they should be calculated. You could reasoning so that more systems have to split the problem in more simple portions and at the end each their results can be brought together (synergically). You can also think about a system that assign a particular task to another (master-slave) or even that two or more systems enter somehow in competition with each other (concurrently).
In fact, this way of thinking can be quite complex and sometimes some solutions can lead to unexpected effects. Generally, if properly developed, a parallel algorithm proves to be much more efficient than one serial, especially when you have to perform complex calculations or operate on huge dataset.
The Message Passing
Among the different models of parallel computation, the Message Passing proved to be one of the most efficient. This paradigm is especially suitable for distributed memory architectures. In this model the threads are located on one or more machines and communicate with each other through messages via Ethernet.
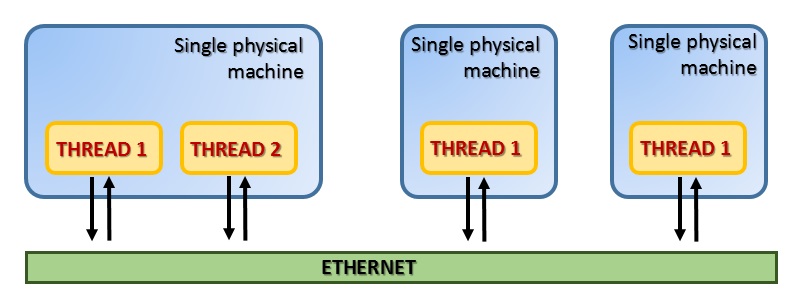
This model is based on a specific protocol called MPI (Message Passing Interface). It consists mainly of a portable and standardized system of message-passing, that currently has become the standard de facto for parallel communication within clusters. Since its first release the standard library MPI has become the most widespread.
This standard protocol has reached version 3.0 (2012) (see here) and at the moment, there are various libraries that are implementing this protocol and the underlying model. The most used library is MPI (OpenMPI) which is the one we’ll use in our examples.
For our own clustering made of Raspberry Pi board we will use the Message Passing model using the MPI protocol and the OpenMPI library which in Python is implemented by the MPI for Python module, called also mpi4py.
mpi4py – MPI for Python
The mpi4py module provides an object oriented approach to message passing to integrate the Python programming. This interface is designed according to the syntax and semantics of MPI defined by the MPI-2 C ++ bindings. You can go deep into this topic consulting a good documentation in this page, it is written by the author of mpi4py, Lisando Dalcin. The examples reported in this article are in fact extracts from his documentation.
Installation
If you want to install this module on Linux (Ubuntu – Debian)
$ sudo apt-get install python-mpi4py
Instead if you prefer to use PyPA to install the package, insert the following command.
$ [sudo] pip install mpi4py
Send and receive Python objects with Communicators
The MPI for Python interface implements the Message Passing model through the MPI protocol. Thus the key feature of this interface is the ability to communicate data and commands (Python objects) among systems. Behind this operation the special functionalities of a module called pickle are exploited. This module allows you to build binary representations (pickling) of any Python object (both built-in and user-defined). These binary representations can be so sent between systems thus in this way you can exchangw data and instructions required for parallel computing. The binary representations once reached the system, are restored in their original form, that is the original Python object (unpickling).
This option also allows the communication between heterogeneous systems, i.e. cluster composed of systems with different architectures. In fact Python objects sent as binary representations can be reconstructed by the receiving system in accordance with its particular architecture.
In the MPI library, the various threads are organized in groups called communicators. All threads within a given communicator can talk to each other, but not with external threads to it.
The object of the mpi4py module that implicitly performs all the functions of communication is the Comm object, which stands for communicator. There are two default instances of this class:
- COMM_SELF
- COMM_WORLD
Through them you can create all new communicators you will need. In fact, when the MPI protocol is activated, a default communicator is created containing all available threads. To start an MPI you just need to import the module.
from mpi4py import MPI
To send messages you have to be able to address the thread inside the Communicator. These threads are recognizable through two numbers associated with them:
- the process number, obtainable with the Get_size() function.
- the rank, obtainable with the Get_rank() function.
So once you have created a Communicator object, the next step is to know how many threads exist and what their rank is.
comm = MPI.COMM_WORLD rank = comm.Get_rank() size = comm.Get_size()
Types of communications
Every communication is carrying tags. These provide a means of recognition by the receiver so that it can understand whether or not to consider it, and in what manner to act.
Before you begin to develop the code, analyzing the parallel algorithm that will allow us to carry out our project, it is necessary to think about what type of communication implement. In fact, there are two types of communication:
- Blocking
- Non-blocking
These two types of communication differ depending on how we want that the two communication systems behave..
The Blocking communication
Generally communications that exist between the various systems in a cluster are blocking. These functions, in fact, block the caller until the data involved in the parallel communication are not returned by the receiver. Therefore the sender program will not continue as long as it wait for the results necessary to continue. The methods send(), recv() and sendrecv() are the methods to communicate generic Python objects. Whereas methods such as Send() and Recv() are used to enable the transmission of large data arrays such as the NumPy array.
The Nonblocking communication
Certain types of calculation may require an increase in performance and this can be achieved by ensuring that the systems can communicate independently, i.e. they can send and share data for the calculation without waiting for any response from the receiver. MPI also provides nonblocking functions for this kind of communication. There will be a call-reception function that starts the action and a control function that allow you to find out if such a request was completed. The call-reception functions are lsend() and lrecv(). These functions return a Request object, which uniquely identifies the requested operation. Once this operation has been sent you can check its performance through control functions such ad Test(), Wait() and Cancel() belonging to the Request class.
Persistent communication
There is also another type of communication, although actually you can consider it as a non-blocking communication. Often during the drafting of the code, you might notice that some communication requests are executed repeatedly as they are located within a loop. In these particular cases, you can optimize the performance of the code by using persistent communications. The functions of the mpi4py module performing this task are Send_init() and Recv_init(). They belong to the Comm class and create a persistent request by returning an object of type Prequest.
Now let’s see how to code a blocking communication. You have seen that for sending data you can use the send() function.
data = [1.0, 2.0, 3.0, 4.0] comm.send(data, dest=1, tag=0)
With this command, the values contained in data are sent to the target thread with rank = 1 (defined by the dest option passed as the second argument). The third parameter is a tag that can be used in the code to label different types of message. In this way the receiver thread can behave differently depending on the type of message.
As far as the receiving system you will write the recv() function.
data = comm.recv(source = 0, tag = 0)
Let’s build the cluster of Raspberry Pi
In this article I will explain my simple cluster consisting of two Raspberry Pi B+. However the principles and commands that I will use, will be the same for any cluster system you implement, independently how it is extended.
First I added a Wireless USB on each Raspberry Pi.

and I added them to my home network.

Thus, after turning on the two Raspberry, I connected via SSH to the two systems with my laptop. If you have Windows as operating system, you can use the Putty application (download it here).
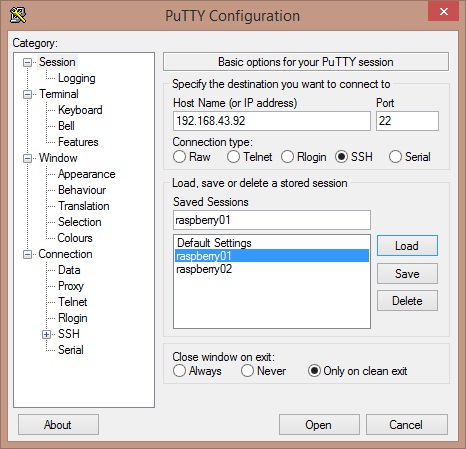
If instead you have a Linux system, simply enter this command line (if your user is pi):
ssh pi@192,168.43.92
and then insert you password.
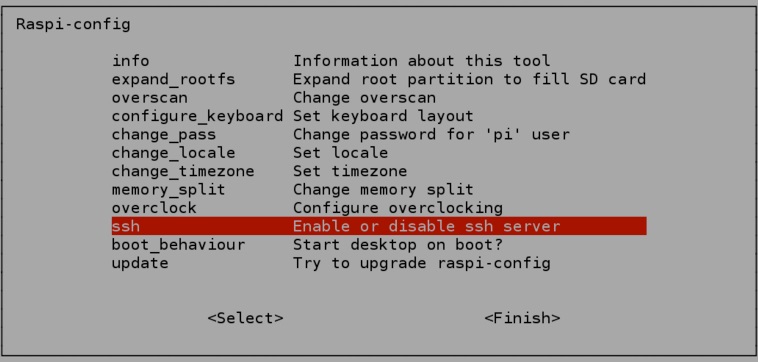
Just in case it does not work, it is very likely that you did not enable the SSH on the two Raspbìan. To enable SSH write
sudo raspi-config
and then you can enable SSH by selecting the corresponding entry in the configuration menu
At this point I want to mention that if you want to continue with the examples, you must have already installed MPI for Python on both of the two Raspbian Raspberry.
You should now have everything to start. Every example of Python code below, saved as a .py file must be copied on both machines, and then run on one of the two running the mpiexec command.
mpiexec -n 2 --host raspberry01,raspberry02 python my-program.py
In my case I’m using a cluster of two systems, therefore I need to specify 2 as value for the -n option. Then we need to insert the list of IP or hostname of the machines making up the cluster. The first name should be that of the machine on which you are running the mpiexec command. At the end we need to add the command to be run simultaneously on all systems, in this case the execution of a Python program. The file containing the Python code must be present on all machines and must be in the same directory path.
In my case I created a MPI directory which contains all the Python files used for MPI.
First examples of data transfer
The first example will be to transfer a Python built-in object such as a dictionary from the system 0 to the system 1. This is the most basic activity that you have to do in parallel computing and it is a simple example of communication Point-to-Point. Write the following code and save it as first.py.
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
data = {'a': 7, 'b': 3.14}
comm.send(data, dest=1, tag=11)
print('from rank 0: ')
print(data)
else:
data = comm.recv(source=0, tag=11)
print('from '+str(rank)+': ')
print(data)
Personally, I prefer to edit this file on one of the two systems, for example raspberry01 with the nano command, and then I copy it to raspberry02 through SSH with the scp command.
scp MPI/first.py pi@raspberry02:MPI

If you created the file in a path different from the MPI directory, remember to change the command described above. And now it’s time to execute the new created file on raspberry01.
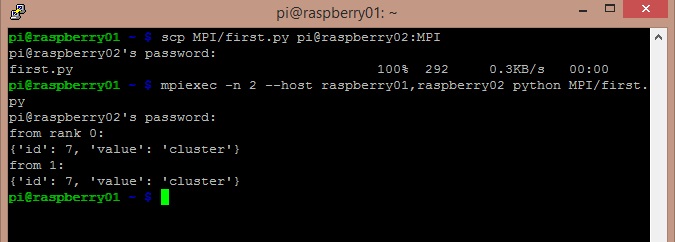
As you can see from the Figure above, the dictionary object has been successfully transferred to the second system raspberry02. The sent object has been converted into binary form by the raspberry01 system and then rebuilt by the receiving system raspberry02.
In a second example, there will be the transfer of a NumPy array between the two systems. In this case, unlike the previous case, you have to use the Send() and Recv() functions (recognizable by the fact that the first letter is capitalized). These functions use a buffering system that makes very efficient the transmission system, comparable to MPI code developed in C language. Copy the following code on one of the systems of the cluster, and then copy it to all others. Save it as numpy_array.py.
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
data = numpy.arange(1000, dtype='i')
comm.Send([data, MPI.INT], dest=1, tag=77)
elif rank == 1:
data = numpy.empty(1000, dtype='i')
comm.Recv([data, MPI.INT], source=0, tag=77)
print('from '+str(rank))
print(data)
The code send a NumPy arrays containing 1000 integers in ascending order from the raspberry01 system to the raspberry02 system.
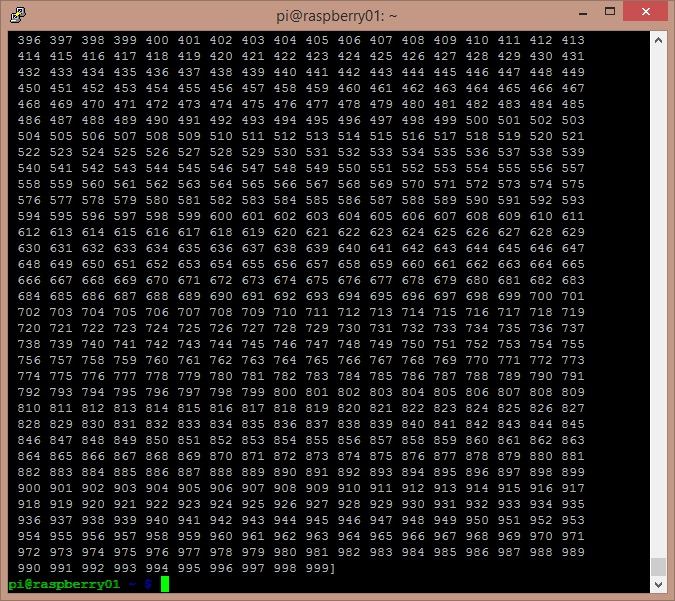
Other examples about collective communications
In the previous examples you saw that the rank 0 is assigned to the master node, which is the system from which you invoke the mpiexec command (raspberry01 in our examples).The master node sent specific messages to a specific system by specifying its rank in the call.
Now you’ll see three examples that cover three different aspects of the collective communication that can occur between multiple systems simultaneously. Unfortunately my cluster consists of just two elements, whereas the following examples would be more appropriate if performed in a cluster of more than 4 elements.
Broadcasting
In this example we will perform a broadcast, that is, the master node will send the same data message simultaneously to all other systems.

First, all data on the other nodes must be set to None. Then the master node sends data to all other via the bcast() function. The following code performs all these tasks. Save it as broadcasting.py and then copy it on all other systems.
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
data = {'key1' : [7, 2.72, 2+3j],
'key2' : ('abc','xyz')}
else:
data = None
data = comm.bcast(data, root=0)
print('from' + str(rank))
print(data)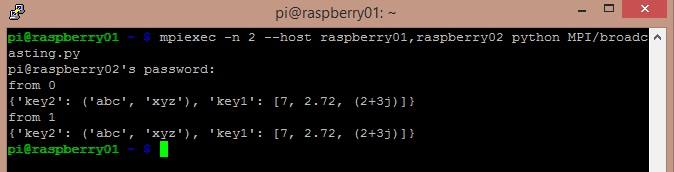{kind=link}
Scattering
The scattering is instead the mode with which the master node may divide a data structure as a list and then distribute it by dividing it into several portions, each transmitted with a respective message to one of the systems that make up the cluster.

This operation is performed by the scatter() function. Also in this case all the other systems before proceeding to the scattering must have the data set to None. Write the following code and save it as scattering.py, then copy it on all other systems.
from mpi4py import MPI comm = MPI.COMM_WORLD size = comm.Get_size() rank = comm.Get_rank() if rank == 0: data = [(i+1)**2 for i in range(size)] else: data = None data = comm.scatter(data, root=0) assert data == (rank+1)**2
{kind=link}
This example assign to each system the calculation of its rank number incremented by a unit and then squared.
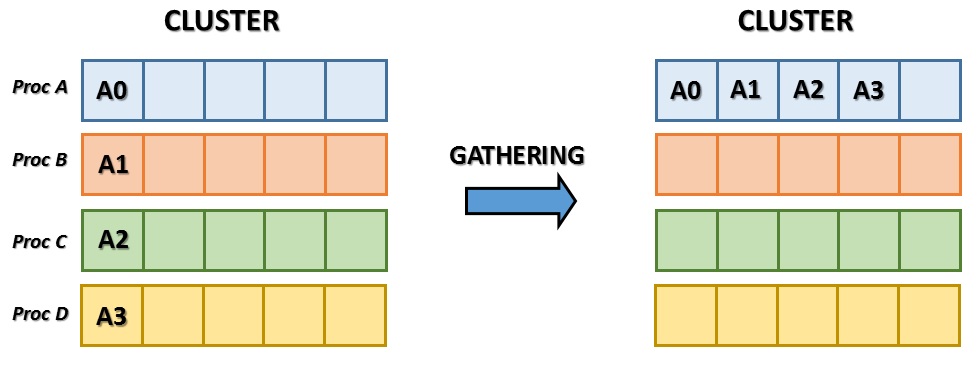
Gathering
The gathering is practically the opposite operation to the scattering. In this case, it is the master node to be initialized and to receive all the data from the other members of the cluster.
Enter the following code and save it as gathering.py, then copy it on all other systems..
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
data = (rank+1)**2
data = comm.gather(data, root=0)
if rank == 0:
for i in range(size):
assert data[i] == (i+1)**2
else:
assert data is None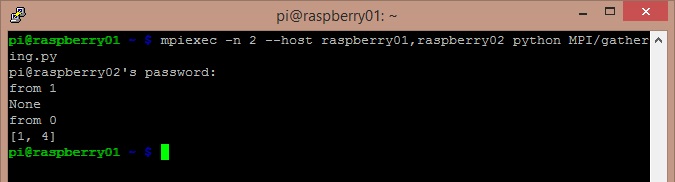{kind=link}
In this example you can see how the master node receives all the results of the calculation from the other nodes of the cluster. The results are the same of the previous example, obtained by calculating the rank of a value added by a unit and then squared
Example of Parallel Calculation: the calculation of the π value
To conclude the article you will examine the calculation of π. I found a beautiful example for this type of calculation developed by jcchurch, and whose code is available on GitHub.
I made some small changes to measure some features such as the elapsed time and the error of the value of π calculated. For convenience I copied the code in this page.
from mpi4py import MPI
import time
import math
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
# I will change these parameters for the performance table
slice_size = 1000000
total_slices = 50
start = time.time()
pi4 = 0.0
# This is the master node.
if rank == 0:
pi = 0
slice =
process = 1
print size
# Send the first batch of processes to the nodes.
while process < size and slice < total_slices:
comm.send(slice, dest=process, tag=1)
print "Sending slice",slice,"to process",process
slice += 1
process += 1
# Wait for the data to come back
received_processes = 0
while received_processes < total_slices:
pi += comm.recv(source=MPI.ANY_SOURCE, tag=1)
process = comm.recv(source=MPI.ANY_SOURCE, tag=2)
print "Recieved data from process", process
received_processes += 1
if slice < total_slices:
comm.send(slice, dest=process, tag=1)
print "Sending slice",slice,"to process",process
slice += 1
# Send the shutdown signal
for process in range(1,size):
comm.send(-1, dest=process, tag=1)
pi4 = 4.0 * pi
#print "Pi is ", 4.0 * pi
# These are the slave nodes, where rank > 0. They do the real work
else:
while True:
start = comm.recv(source=0, tag=1)
if start == -1: break
i = 0
slice_value = 0
while i < slice_size:
if i%2 == 0:
slice_value += 1.0 / (2*(start*slice_size+i)+1)
else:
slice_value -= 1.0 / (2*(start*slice_size+i)+1)
i += 1
comm.send(slice_value, dest=0, tag=1)
comm.send(rank, dest=0, tag=2)
if rank == 0:
end = time.time()
error = abs(pi4 - math.pi)
print ("pi is approximately %.10f, "
"error is %.10f" % (pi4,error))
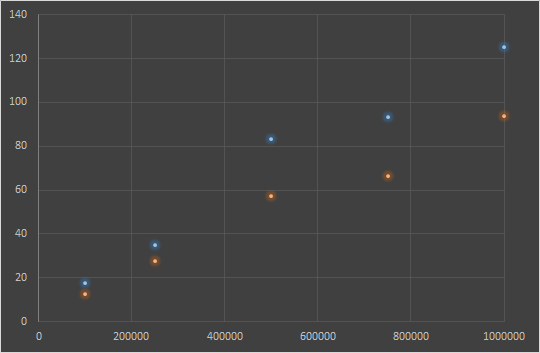
print ("elapsed time: %.2f" % (end - start))I have collected the elapsed time for the calculation while maintaining constant the number of slices, but varying their size (SLICE_SIZE).
SLICES = 10
| SLICE SIZE | CLUSTER NODES = 1 (time elapsed) | CLUSTER NODES = 2 (time elapsed) |
| 100000 | 17.72 | 12.77 |
| 250000 | 35.15 | 27.50 |
| 500000 | 83.11 | 57.31 |
| 750000 | 93.16 | 66.39 |
| 1000000 | 125.07 | 93.55 |
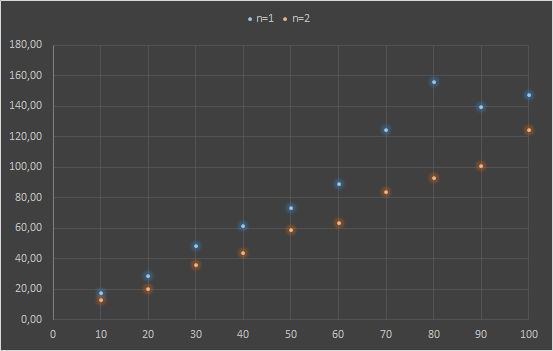
Now let’s see the time required for the calculation by keeping constant the size of the slice but increasing their number.
SLICESIZE = 100000
| SLICES | CLUSTER NODES = 1 (time elapsed) | CLUSTER NODES = 2 (time elapsed) |
| 10 | 17.72 | 12.77 |
| 20 | 28.46 | 20.27 |
| 30 | 48.49 | 35.49 |
| 40 | 61.53 | 43.72 |
| 50 | 73.11 | 58.64 |
| 60 | 89.08 | 63.52 |
| 70 | 124.47 | 83.56 |
| 80 | 156.14 | 92.92 |
| 90 | 139.66 | 101.02 |
| 100 | 147.11 | 124.36 |
[:]