




In questo articolo, esploreremo insieme le differenze che ci sono tra la statistica descrittiva e la statistica inferenziale, evidenziando i loro ruoli specifici nell’analisi statistica e illustrando come possano essere utilizzati in modo complementare per ottenere una comprensione completa dei dati.
Statistica Descrittiva vs Statistica Inferenziale
La statistica descrittiva si concentra sulla presentazione e sull’organizzazione dei dati in modo chiaro e comprensibile. Include misure centrali come la media, la mediana e la moda, nonché la deviazione standard e l’intervallo. In sostanza, la statistica descrittiva riassume e descrive le caratteristiche principali di un insieme di dati senza fare alcuna inferenza oltre a ciò che è osservato.
D’altra parte, la statistica inferenziale va oltre la semplice descrizione dei dati. Si basa sull’uso di campioni per fare inferenze o previsioni sulla popolazione più ampia da cui proviene il campione. Questo tipo di statistica include test di ipotesi, stime di intervallo e regressione. L’obiettivo è fare affermazioni o previsioni generalizzabili sulla popolazione basandosi su un campione rappresentativo.
In breve, mentre la statistica descrittiva riassume e organizza i dati, la statistica inferenziale trae conclusioni più ampie e fa previsioni basate su tali conclusioni. Entrambe sono cruciali nel campo della statistica, poiché lavorano in sinergia per fornire una comprensione completa dei dati e per supportare decisioni informate.
Esempio con Python
Supponiamo di avere un set di dati che rappresenta l’altezza di un gruppo di studenti e vogliamo esplorare sia la statistica descrittiva che quella inferenziale su tale campione utilizzando del codice Python.
import numpy as np
from scipy import stats
# Creiamo un set di dati (altezza in centimetri)
campione_altezze = [160, 165, 170, 155, 175, 180, 162, 168, 172, 158]
# Statistica Descrittiva
media_altezze = np.mean(campione_altezze)
mediana_altezze = np.median(campione_altezze)
deviazione_std = np.std(campione_altezze)
print(f"Media delle altezze: {media_altezze:.2f} cm")
print(f"Mediana delle altezze: {mediana_altezze:.2f} cm")
print(f"Deviazione standard delle altezze: {deviazione_std:.2f} cm")
# Statistica Inferenziale
livello_di_confidenza = 0.95
intervallo_di_confidenza = stats.norm.interval(livello_di_confidenza, loc=media_altezze, scale=deviazione_std/np.sqrt(len(campione_altezze)))
print(f"\nIntervallo di confidenza del {livello_di_confidenza * 100}% per la media delle altezze: ({intervallo_di_confidenza[0]:.2f} cm, {intervallo_di_confidenza[1]:.2f} cm)")
# Esempio di test di ipotesi (ipotizziamo che la media sia 170 cm)
ipotesi_media = 170
t_stat, p_value = stats.ttest_1samp(campione_altezze, ipotesi_media)
print(f"\nTest di ipotesi:")
print(f"T-statistic: {t_stat:.4f}")
print(f"P-value: {p_value:.4f}")
# Valutazione del t-value
if abs(t_stat) > 2:
print("\nIl valore t è significativamente diverso da zero")
else:
print("\nIl valore t non è significativamente diverso da zero")
# Confrontiamo il p-value con un livello di significatività (ad esempio, 0.05)
livello_di_significatività = 0.05
if p_value < livello_di_significatività:
print("La media delle altezze nel campione è significativamente diversa da 170 cm.")
else:
print("Non ci sono evidenze sufficienti per respingere l'ipotesi che la media delle altezze sia 170 cm.")Eseguendo il codice, si ottiene come risultato delle due analisi statistiche sul campione delle altezze:
Media delle altezze: 166.50 cm
Mediana delle altezze: 166.50 cm
Deviazione standard delle altezze: 7.54 cm
Intervallo di confidenza del 95.0% per la media delle altezze: (161.83 cm, 171.17 cm)
Test di ipotesi:
T-statistic: -1.3926
P-value: 0.1972
Il valore t non è significativamente diverso da zero
Non ci sono evidenze sufficienti per respingere l'ipotesi che la media delle altezze sia 170 cm.L’esempio di codice fornito utilizza Python e le librerie NumPy e SciPy per illustrare l’applicazione della statistica descrittiva e inferenziale a un campione di dati. Ecco una descrizione dettagliata del codice:
- Selezione del Campione:
Per prima cosa, si deve selezionare nel mondo reale un campione di valori in numero sufficiente, o rappresentativo, che possa rappresentare al meglio le altezze di un gruppo di soggetti a cui vogliamo sottoporre un’analisi statistica.
campione_altezze = [160, 165, 170, 155, 175, 180, 162, 168, 172, 158]- Statistica Descrittiva:
Calcoliamo la media, la mediana e la deviazione standard del campione.
media_altezze = np.mean(campione_altezze)
mediana_altezze = np.median(campione_altezze)
deviazione_std = np.std(campione_altezze)- Stampa delle Misure Descrittive:
Stampiamo i risultati delle misure descrittive per avere un’idea delle caratteristiche principali del campione.
print(f"Media delle altezze: {media_altezze:.2f} cm")
print(f"Mediana delle altezze: {mediana_altezze:.2f} cm")
print(f"Deviazione standard delle altezze: {deviazione_std:.2f} cm")- Statistica Inferenziale – Intervallo di Confidenza:
Calcoliamo un intervallo di confidenza del 95% per la media delle altezze nel campione utilizzando la distribuzione normale.
livello_di_confidenza = 0.95
intervallo_di_confidenza = stats.norm.interval(livello_di_confidenza, loc=media_altezze, scale=deviazione_std/np.sqrt(len(campione_altezze)))- Stampa dell’Intervallo di Confidenza:
Stampiamo l’intervallo di confidenza calcolato.
print(f"\nIntervallo di confidenza del {livello_di_confidenza * 100}% per la media delle altezze: ({intervallo_di_confidenza[0]:.2f} cm, {intervallo_di_confidenza[1]:.2f} cm)")- Statistica Inferenziale – Test di Ipotesi:
Eseguiamo un test di ipotesi per verificare se la media delle altezze nel campione è significativamente diversa da 170 cm.
ipotesi_media = 170
t_stat, p_value = stats.ttest_1samp(campione_altezze, ipotesi_media)- Stampa dei Risultati del Test di Ipotesi:
Stampiamo la statistica t e il p-value associato al test di ipotesi.
print(f"\nTest di ipotesi:")
print(f"T-statistic: {t_stat:.4f}")
print(f"P-value: {p_value:.4f}")- Valutazione di T-stat :
Un t-value maggiore in valore assoluto indica che la differenza tra la media del campione e la media ipotizzata è più grande rispetto a quanto ci si aspetterebbe casualmente. In altre parole, suggerisce una maggiore discrepanza tra il campione e l’ipotesi nulla. Quindi riteniamo che t-value maggiori di 2 ( o -2 ) indichino che la nostra ipotesi di una media di 170cm non sia vera.
if abs(t_stat) > 2:
print("\nIl valore t è significativamente diverso da zero")
else:
print("\nIl valore t non è significativamente diverso da zero")- Decisione Basata sul P-value:
Confrontiamo il p-value con un livello di significatività (0.05) per decidere se respingere o non respingere l’ipotesi nulla.
if p_value < livello_di_significatività:
print("La media delle altezze nel campione è significativamente diversa da 170 cm.")
else:
print("Non ci sono evidenze sufficienti per respingere l'ipotesi che la media delle altezze sia 170 cm.")Questo esempio dimostra come utilizzare sia la statistica descrittiva che quella inferenziale su un campione di dati, fornendo una panoramica completa delle caratteristiche del campione e delle deduzioni che possiamo fare sulla popolazione da cui il campione è stato estratto.
Questo codice illustra come combinare la statistica descrittiva e quella inferenziale in Python per analizzare un set di dati.


Libro consigliato:
Se ti piace quest’argomento, ti consiglio questo libro:
Statistica inferenziale: Valutazione del p-value e del t-statistic
Nell’esempio precedente abbiamo visto come valutare l’esattezza di una media stimata di 170cm su di un campione di altezze in base ai valori ottenuti dalla statistica inferenziale p-value e t-statistic. Spieghiamo meglio questo punto.
Per quanto riguarda il p-value la valutazione è abbastanza semplice. Per prima cosa dobbiamo stabilire un livello di significatività. Il livello di significatività, spesso indicato con 

Il p-value , invece, è la probabilità di ottenere un risultato almeno tanto estremo quanto quello osservato nel campione, assumendo che l’ipotesi nulla sia vera. In termini più semplici, rappresenta la probabilità di osservare i dati del campione se l’ipotesi nulla è corretta.
Nel test di ipotesi, si confronta il p-value con il livello di significatività. Se il p-value è inferiore al livello di significatività prescelto, di solito si respinge l’ipotesi nulla. In altre parole, un p-value basso suggerisce che i dati del campione sono statisticamente significativi e forniscono evidenze contro l’ipotesi nulla. Se 



In termini più concreti, un livello di significatività del 0.05 indica che si è disposti a commettere un errore di tipo I con una probabilità del 5%. Se il p-value è inferiore a 0.05, si respinge l’ipotesi nulla, affermando che ci sono evidenze statistiche significative contro di essa. Se il p-value è maggiore o uguale a 0.05, non si respinge l’ipotesi nulla, indicando che non ci sono evidenze statistiche significative per respingerla.
In breve, il confronto tra il p-value e il livello di significatività aiuta a prendere decisioni informate sul respingere o non respingere l’ipotesi nulla in base alle prove statistiche disponibili.
Il valore t-statistic (o t-value) è una misura di quanto la media del campione si discosti dalla media ipotizzata nella popolazione, espresso in termini di deviazioni standard del campione. Ecco come interpretare il valore t-statistic:
- Maggiori Deviazioni Standard (in valore assoluto): Un t-value maggiore in valore assoluto indica che la differenza tra la media del campione e la media ipotizzata è più grande rispetto a quanto ci si aspetterebbe casualmente. In altre parole, suggerisce una maggiore discrepanza tra il campione e l’ipotesi nulla.
- Valori Positivi e Negativi: Un t-value positivo indica che la media del campione è superiore alla media ipotizzata, mentre un t-value negativo indica che la media del campione è inferiore alla media ipotizzata.
- Confronto con Livello di Significatività: Per determinare se la discrepanza tra la media del campione e la media ipotizzata è statisticamente significativa, si confronta il t-value con un valore critico noto come valore critico di t o si guarda il p-value associato al t-value.
- Decisione sulle Ipotesi: Se il t-value è grande e il p-value è basso (inferiore al livello di significatività prestabilito), si può respingere l’ipotesi nulla. Questo indica che ci sono prove statistiche sufficienti per affermare che la media del campione è significativamente diversa dalla media ipotizzata.
In sostanza, il t-value rappresenta quanto la media del campione si discosti dalla media ipotizzata, e un t-value più grande in valore assoluto suggerisce una maggiore forza delle evidenze contro l’ipotesi nulla. La valutazione finale dipende dal contesto specifico, dal valore critico di t e dal livello di significatività scelto per il test.
Altro esempio con un’ipotesi di media errata
Nel caso precedente abbiamo visto come l’ipotesi di un’altezza media di 170cm sia conforme al campione in analisi. Vediamo un altro esempio, in cui questa ipotesi non è valida. In questo esempio, genererò un nuovo campione di altezze con una media di 165 cm anziché 170 cm, ottenendo i valori da una distribuzione normale. Eseguendo il test di ipotesi sulla nuova media, otterremo un p-value che indica che la media del campione è significativamente diversa dall’ipotesi di 170 cm.
import matplotlib.pyplot as plt
# Genera un campione con una media diversa da 170 cm
campione_non_conforme = np.random.normal(loc=165, scale=8, size=100)
# Esegui il test di ipotesi
t_stat_non_conforme, p_value_non_conforme = stats.ttest_1samp(campione_non_conforme, ipotesi_media)
# Plot della distribuzione del campione
plt.figure(figsize=(12, 6))
plt.hist(campione_non_conforme, bins=20, color='blue', alpha=0.7)
plt.axvline(x=np.mean(campione_non_conforme), color='red', linestyle='dashed', linewidth=2, label='Media campione')
plt.title('Distribuzione del Campione Non Conforme')
plt.xlabel('Altezza (cm)')
plt.ylabel('Frequenza')
plt.legend()
# Mostra i grafici
plt.tight_layout()
plt.show()
print(f"\nHypothesis testing:")
print(f"T-statistic: {t_stat_non_conforme:.4f}")
print("p_value: ", p_value_non_conforme)
# Decisione basata sul p-value
livello_di_significatività = 0.05
# Valutazione del t-value
if abs(t_stat_non_conforme) > 2:
print("\nIl valore t è significativamente diverso da zero")
else:
print("\nIl valore t non è significativamente diverso da zero")
if p_value_non_conforme < livello_di_significatività:
print("La media delle altezze nel campione NON è coerente con l'ipotesi di 170 cm.")
else:
print("Non ci sono evidenze sufficienti per respingere l'ipotesi che la media delle altezze sia 170 cm.")By running the code we will obtain the following result:
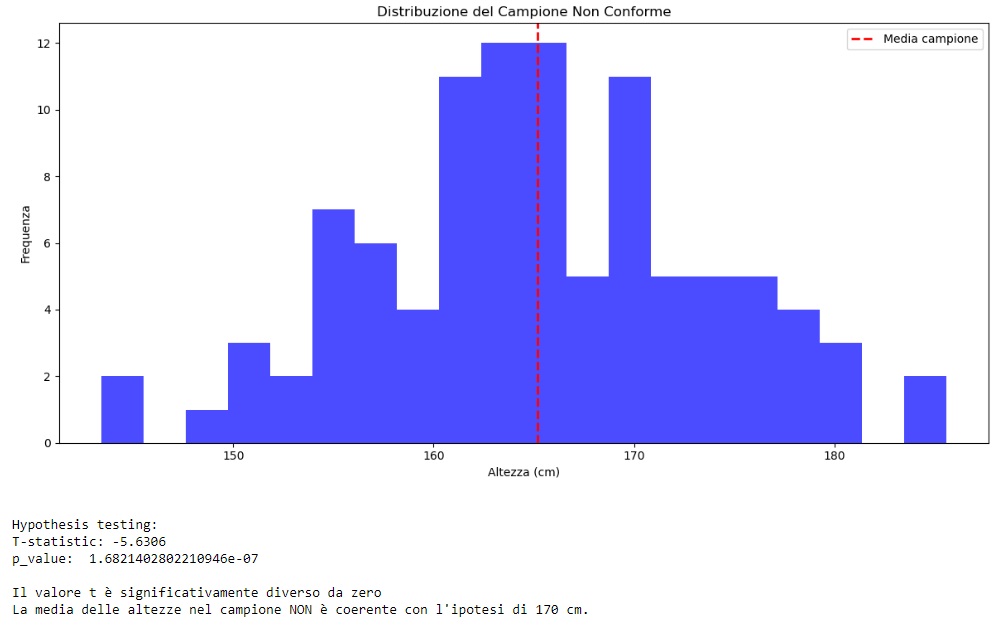


Se vuoi approfondire l’argomento e scoprire di più sul mondo della Data Science con Python, ti consiglio di leggere il mio libro:
Fabio Nelli
Ulteriori Considerazioni tra statistica descrittiva e statistica inferenziale
L’analisi descrittiva e l’analisi inferenziale sono due approcci distinti nella statistica, ciascuno con un ruolo specifico nell’interpretazione dei dati. Quando ci si avvicina a un set di dati, l’analisi descrittiva è spesso il primo passo. Questo approccio mira a fornire una panoramica completa delle caratteristiche principali del campione, utilizzando misure come la media, la mediana, la deviazione standard e altre per descrivere la distribuzione e la variabilità dei dati.
D’altra parte, l’analisi inferenziale si concentra sulla formulazione di conclusioni generali sulla popolazione totale basandosi su un campione rappresentativo. Questo tipo di analisi include test di ipotesi, intervalli di confidenza e altre tecniche che consentono di fare deduzioni sulla popolazione in base alle informazioni raccolte dal campione.
Inoltre, come abbiamo visto nell’esempio precedente, l’analisi descrittiva spesso coinvolge la visualizzazione dei dati tramite grafici, mentre l’analisi inferenziale si basa anche su grafici ma si concentra più sulla comunicazione dei risultati dei test di ipotesi.
Nel confronto tra i due approcci, è importante notare che l’analisi descrittiva fornisce una visione iniziale e comprensibile dei dati, mentre l’analisi inferenziale aggiunge un livello di profondità, consentendo di trarre conclusioni più ampie sulla popolazione. Tuttavia, l’analisi inferenziale comporta il rischio di errori, come l’errore di tipo I e l’errore di tipo II, e richiede spesso l’osservanza di alcune assunzioni fondamentali.
Entrambi gli approcci sono spesso utilizzati congiuntamente in un’analisi statistica completa. L’analisi descrittiva aiuta a comprendere la struttura e le caratteristiche del dataset, mentre l’analisi inferenziale consente di fare dichiarazioni più avanzate sulla popolazione di riferimento. La scelta tra i due dipende dagli obiettivi specifici dell’analisi e dalla natura dei dati disponibili, garantendo un approccio equilibrato e informativo all’interpretazione dei risultati.