Questo articolo è collegato all’articolo Hexagonal Binning in cui viene mostrata questa metodica di aggregazione di dati partendo da una rappresentazione scatterplot per poi finire con una rappresentazione che usa hexagonal bins. I grafici rappresentati in quell’articolo sono stati realizzati utilizzando la libreria JavaScript D3.

Nel corso dell’articolo vedremo come sia possibile sottoporre un insieme di dati (scritti nel formato CSV) a varie analisi mediante l’uso esclusivo della libreria D3. A titolo di esempio, utilizzeremo due dataset contenuti in due diversi file CSV. Per prima cosa vedremo come sia possibile rappresentarli come scatterplot, e successivamente, dopo essere stati sottoposti al binning esagonale, come visualizzarli come heatmap esagonali.
(In un altro articolo è stata presa in considerazione la tecnica del binning rettangolare).

Per chi non avesse dimestichezza con la realizzazione di grafici utilizzando librerie JavaScript consiglio vivamente di leggere il libro Beginning JavaScript Charts with jqPlot, D3 and Highcharts. In questo libro sono contenuti numerosissimi esempi (oltre 250 esempi) in cui passo per passo vengono spiegati come si realizzano le tipologie più comuni di grafici su Web utilizzando diverse librerie JavaScript.
Ecco i due dataset salvati come file CSV:
- scatterplot01 : è il dataset che genera lo scatterplot “sparso”
- scatterplot02 : è il dataset che genera lo scatterplot con andamento lineare
Per comprendere bene come si distribuiscano nello spazio i dati contenuti nei due files, sviluppiamo una pagina web che sia in grado di generare delle rappresentazioni scatterplot. Il codice della pagina è quello seguente. Una volta copiato in un editor di testo, salvatelo come scatterplot01.html.
Questa pagina legge il contenuto del file scatterplot01.csv. Per poter leggere il contenuto del secondo file, sostituite il nome del file con quello nuovo, come mostrato qui:
d3.csv("scatterplot02.csv", function(error, data) {e salvate la pagina web modificata come scatterplot02.html.
Questo è lo scatterplot prodotto dall’insieme di dati contenuto nel file scatterplot02.csv.
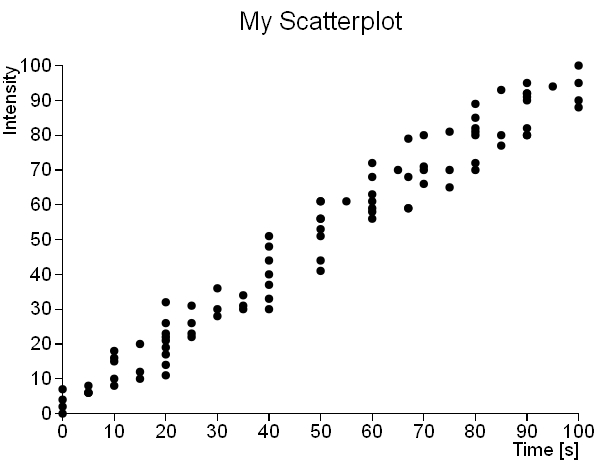
e questo è lo scatterplot prodotto utilizzando i dati contenuti nel file scatterplot01.csv.
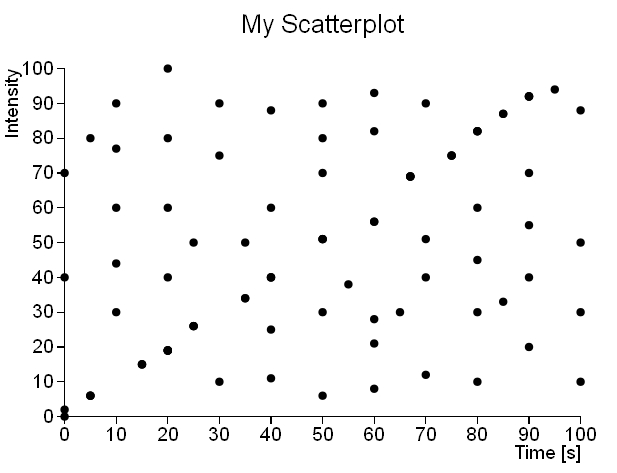
Come possiamo vedere, è facilmente evidente che il dataset scatterplot02 segue un andamento lineare, mentre il dataset scatterplot01 non mostra alcun cluster o andamento particolare. Quindi, mentre nel primo caso una rappresentazione scatterplot può essere sufficiente per effettuare un’analisi sull’insieme di dati, nel secondo caso è necessario applicare un metodo di analisi diverso, che tenga conto anche delle densità di distribuzione dei punti nello spazio rappresentato dal piano XY. Un metodo di aggregazione molto efficiente a cui sottoporre il dataset “sparso” è proprio il binning esagonale.
La libreria D3 ci fornisce un plugin specializzato proprio per questo tipo di analisi: d3.hexbin.js. Questo plugin contiente un layout che è in grado, una volta fornito un dataset, di effettuare un binning esagonale su di esso, generando una struttura dati corrispondente. Questa struttura dati, contiene i bin in cui è stato suddiviso il piano XY indicizzati per i valori i e j, i punti che contiene ciascuna bin, la coordinata del centro dell’esagono e il conteggio dei punti racchiusi. Grazie ai valori contenuti in questa struttura dati spetterà poi alle funzioni grafiche della libreria D3 convertire tali dati in elementi grafici.
Ecco qui il codice della pagina web che ci permetterà di effettuare il binning esagonale sui vari dataset.

Come possiamo vedere dalla figura, dove prima avevamo una distribuzione uniforme, è ben evidente un andamento lineare tracciato dagli esagoni di color rosso scuro che tagliano diagonalmente il piano XY.
Se applichiamo il binning esagonale al dataset che già presentava nello scatterplot un andamento lineare otteniamo il grafico seguente:
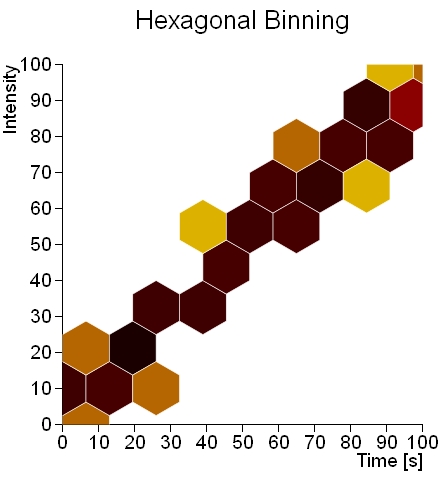
Come è ben visibile, è praticamente superfluo applicare questo tipo di analisi a questa categoria di dataset.