



Introduction
{kind=link}
In all programming languages, data structure models are an important element for managing advanced programming. So it’s very important to be familiar with them and how to use them. Graphs are a very important data structure. Python does not have a primitive data structure to handle the graphs, so it is necessary to implement it. In this article you will see what are the graphs, their features, and how to implement some useful features for managing and manipulating the data inside.

Graphs
First, let’s find out what the graphs are. In the article, the concept of graph will become easier as its features are specified through graphics definitions and graphics.
First, a graph is made up of a series of nodes, generally indicated by balls, some of which are connected to each other. The edges are represented by lines connecting two nodes.
The following figure shows a typical representation of a graph.
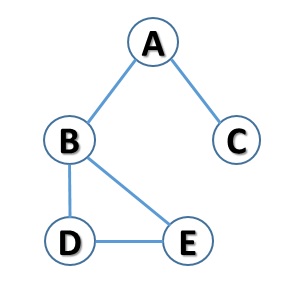
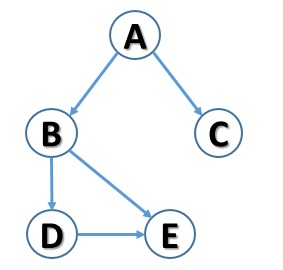
The edges can be represented in two different ways: with a simple line if the connection does not have a direction, otherwise with an arrow if the connection is directed from one node to another (arc). A graph that has connections with directions is generally referred to as a directed graph.
Of course you will have noticed that many systems follow this type of model. In computer science, just think of computers connected to a network or Facebook with users and their friendships or group memberships. But this model can also be found in so many other systems of the world of physics, biology, chemistry (just think of molecules), and also of statistics and economics.
In fact, the models of these data structures are used to organize and contain objects or elements, and it is therefore crucial to implement them through programming languages. Especially when you need to work on data structures that follow this type of model.
Before you start, a small premise. As for the implementation in Python, much of the code in this article was taken from the page on the graphs on the Python Course.site. In this article, I’ve made some code changes to make it more readable and easily adaptable to teaching needs.
A graph implementation in Python using dictionaries
Python, as well as many other programming languages, does not have default data structures to specify graphs, so it is necessary to implement this model. For this purpose, simpler data structures are commonly used, and as for Python, one of these data structures that is right in our case is the dictionary. In fact, you will use its key-value structure to indicate any graph, using as few lines as possible.
One important thing to consider: Choosing dictionaries is not mandatory, indeed, you can also use other data structures. But once you have chosen the basic data structure to represent the model, you will not be able to go back any more, as all of the functions implemented later will refer closely to it.
If you take as the reference the graph shown in the previous figure, you will have the following implementation:
graph = { "A" : ["B", "C"],
"B" : ["D", "E", "A"],
"C" : ["A"],
"D" : ["B", "E"],
"E" : ["B", "D"]
}As you can see, the dictionary keys indicate the nodes of the graph, and as a value for each of them, the list of nodes connected to it is expressed through a list.
The only problem with this representation of the graph is that you have not explicitly expressed the connections between the various nodes but you can implement a function that generates the list, passing as the argument the graph.
Each connection will be expressed through a 2-values tuple that will contain the two connected nodes inside it.
(“A”, “B”)
Now write the function that will give us output a list containing all the edges.
def edges(graph):
edges = []
for node in graph:
for neighbour in graph[node]:
edges.append((node, neighbour))
return edges
print(edges(graph))
If you run the code you will get the following result:

But as you will see right away, there are duplicates. For example, the function returns the connection from node A to node C, but also from node C to node A. Now if you are dealing with a oriented graph, the order of elements within the connection should be relevant, Then (A, C) would not be equal to (C, A). If it was not oriented then (A, C) and (C, A) would represent the same connection (edge). Moreover, existence at the same time of both (A, C) and (C, A) in an oriented graph can create problems (what is the direction of that connection?).
It is therefore better to filter redundant connections (taking into account that the graph is not oriented). If it were orientated, there would be no double representation in the model, but only one of the two.
Then change the above function with this:
def edges(graph):
edges = []
for node in graph:
for neighbour in graph[node]:
if (neighbour, node) not in edge
edges.append((node, neighbour))
return edges
print(edges(graph))
By running the code, you get:

A graph implementation in Python using a class
The implementation you have used so far follows a functional programming scope. Although it is suitable for early implementation approaches, the programming to be considered should be object-oriented. For this reason, you will implement graph representation using a class.
class Graph(object):
def __init__(self, graph=None):
if graph == None:
graph = {}
self.__graph = graphIn this class definition you have made sure that the class builder can also be called without any argument:
Graph()
In that case it will create an empty graph (without nodes and connections) using a dictionary as a data structure. If instead the constructor will be called with a past dictionary as a argument:
Graph(graph)
this will be converted to a graph.
Now that you have implemented the class and builder, you will need to implement some methods.
The first method you will need to take into account is what allows a node to be added to the instantiated object. This will only add a node to the graph, and then to the implementation, a new key-value pair to the dictionary.
def add_node(self, node):
if node not in self.__graph_dict:
self.__graph_dict[node] = []
One very important thing to consider is to check that the node you are inserting in the graph does not already exist inside it. Only in the negative case, there will be the addition of a new node.
From the code you will see that the node that is added has no connection to the rest of the nodes in the graph. This kind of node is called an isolated node.
A second important method to implement is therefore what allows you to create connections between nodes within the graph.
def add_edge(self, edge):
edge = set(edge)
(node1, node2) = tuple(edge)
if node1 in self.__graph:
self.__graph[node1].append(node2)
else:
self.__graph[node1] = [node2]
In this case, the internal control to be performed is to verify the existence of the two nodes within the graph. If so, then a connection will be created between them, adding the value of the other node to the node’s corresponding dictionary key in the list of connected nodes.
Finally, two more methods are needed, especially to test the correct functioning of what we are implementing, which allow us to know the nodes and the edges presently within the graph. Then create these two methods by calling them nodes() and edges().
def nodes(self):
return list(self.__graph_dict.keys())
def edges(self):
edges = []
for node in self.__graph:
for neighbour in self.__graph[node]:
if (neighbour, node) not in edges:
edges.append((node, neighbour))
return edges
Finally, in order to see the status of a graph, you will need to see both nodes and current connections on consoles. To do this, we will implement the __str __ () method that will allow you to display the graph, passing it directly as an argument in the print() function.
def __str__(self):
res = "nodes: "
for node in self.nodes():
res += str(node) + " "
res += "\nedges: "
for edge in self.edges():
res += str(edge) + " "
return res
Let’s try the code
Now that you’ve implemented everything you need as the basis for a graph model. Try to make some examples to see how it works and if everything has been done correctly
First, you have already defined the graph:
graph = { "A" : ["B", "C"],
"B" : ["D", "E"],
"C" : ["A"],
"D" : ["B", "E"],
"E" : ["B", "D"]
}
g = Graph(graph)The instance g will correspond to the following graph:
If you want to see the graph on console, you can write:
print(g)
and you will get:

Now, you have to add the F node.
g.add_node("F")So you’ll have an isolated node.
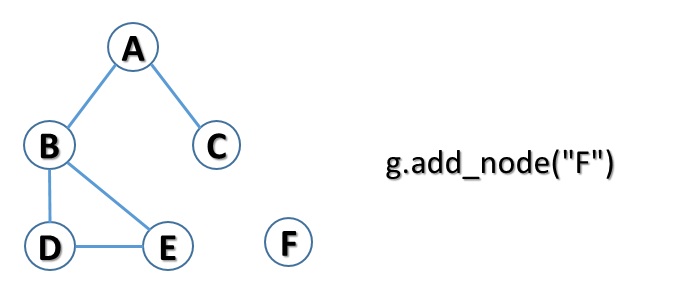
By displaying it on console you will get:

Now you have to create the connection between node C and node F.
g.add_edge(("C","F"))And get the graph
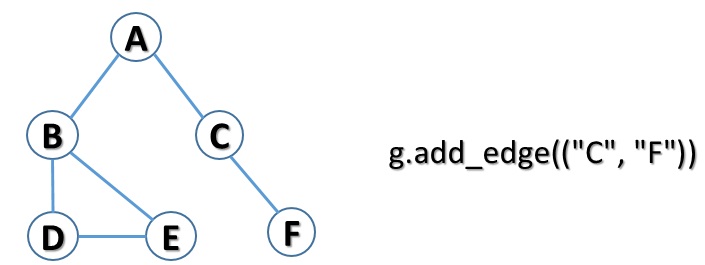

The Graph paths
From the above example, you may already have a good foundation for the graph model. In fact, it is already possible to represent all the graphs in a simple way and at the same time to check the current state of the graph.
Now consider a series of operations that generally take place on graphs. These operations are more or less straightforward for analyzing the state of the graphs. Although the graph of the example is very simple to consider, there are extremely complex graphs, so it is often necessary to use automation to perform analyzes.
The first operation you will take in analysis is the path calculation, ie the possible paths that can be traced on a graph by starting a node to reach another, taking advantage of the connections between them.
The path in a non-oriented graph is:
- sequence of adjacent (connected) nodes P = ( n1, n2, …, nn ) that defines a possible path from a node n1 to a destination nn.
- When the path does not pass more than once on the same node.
Now that you have a definition of what a path is, continue with the sample graph and evaluate a possible path that starts from node A to end in node E.
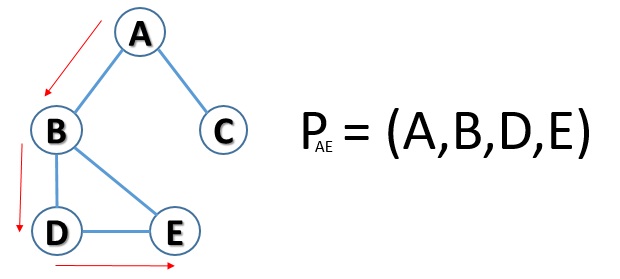
But another possible path is what instead of switching to D, go directly from node B to node D.
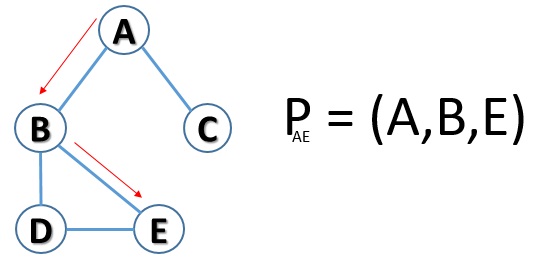
So, on what little you’ve seen, you can already make some considerations. The sample graph is really very simple as it is made up of only 5 knots. However, there are two possible paths between node A and node E. In real examples, with hundreds of nodes, you can imagine the complexity in determining the number of possible paths.
It is also clear that all possible paths, which will certainly be of interest to us, will be the shortest path, that is, the one that will cross as few nodes as possible. So it will be really important to have a number of features that allow us to find the shorter path programmatically by defining any possible graph.
Write the following function within the class (method).
def find_path(self, start_node, end_node, path=None):
if path == None:
path = []
graph = self.__graph_dict
path = path + [start_node]
if start_node == end_node:
return path
if start_node not in graph:
return None
for node in graph[start_node]:
if node not in path:
extended_path = self.find_path(node,
end_node,
path)
if extended_path:
return extended_path
return None
Analyze the function inside it can be seen as both a recursive function, as it recalls itself inside. Starting from the starting node, at each recursion, it adds a node to the path, checking that
- The node is not the node of arrival
- The node is not already present in the path
If you use it with the graph of the previous example:
g = Graph(graph)
path = g.find_path("A","E")
print(path)you will get:

However, this method, as implemented, is not of great use since it only finds one path. What you need is to know all possible paths between two knots. Then define a new method.
def find_all_paths(self, start_vertex, end_vertex, path=[]):
""" find all paths from start_vertex to
end_vertex in graph """
graph = self.__graph_dict
path = path + [start_vertex]
if start_vertex == end_vertex:
return [path]
if start_vertex not in graph:
return []
paths = []
for vertex in graph[start_vertex]:
if vertex not in path:
extended_paths = self.find_all_paths(vertex,
end_vertex,
path)
for p in extended_paths:
paths.append(p)
return paths
Retry the code by using this new method:
g = Graph(graph)
paths = g.find_all_paths("A","E")
print(paths)You will get all the possible paths within the graph between nodes A and E:

You got a list of paths. Now to know which of these is the shortest, just use the command:
print(min(paths, key=len))

Conclusions
In this first part you saw how to implement the graph model in Python using a class to follow object-oriented programming. You have also started implementing some basic operations such as calculating possible paths and searching for the shortest one. In the next article you will see other graph related concepts such as the graph degree and the degree sequence.
[:]