
Statistics
“It is better to be approximately right than precisely wrong.”
John Maynard Keynes (1883-1946) British economist
STATISTICS
Statistics as a key to understanding the world of data
Imagine finding yourself faced with a sea of complex and seemingly chaotic data: company sales, results of scientific experiments, market trends, to name a few. Statistics acts like a magnifying glass, transforming this apparent chaos into a clear and understandable vision. It is the key that unlocks the information potential of each piece of data, allowing us to extract meaning, draw conclusions and make informed decisions.

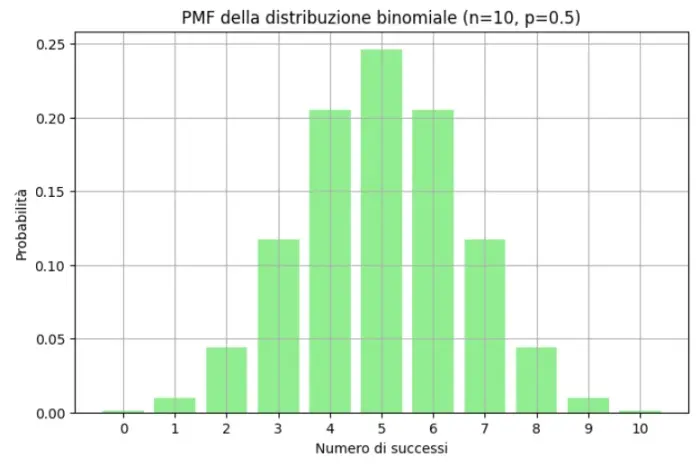
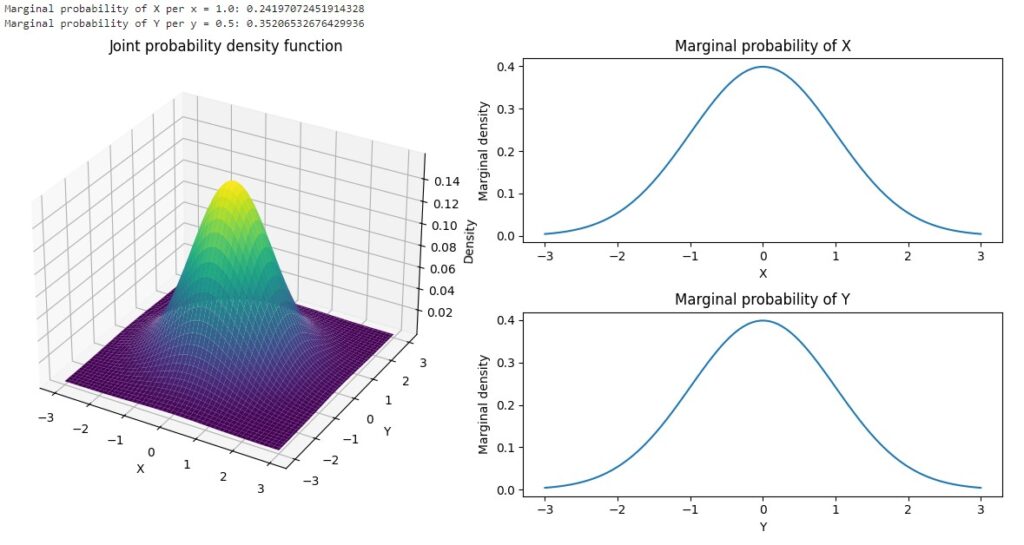
Statistics offers the tools to describe, accurately and synthetically, the essential characteristics of a set of data. Centrality measures such as the mean, median, and mode provide an indication of central tendency, while dispersion measures such as the standard deviation tell us how much the data deviates from the mean. This information is critical to understanding the structure and variability of the data we are exploring.
Python’s role in statistical analysis
In addition to being a powerful programming tool, Python has established itself as a language of choice for statistical and scientific data analysis. Its clear and flexible syntax, wide range of specialized libraries and active community make it an ideal partner for anyone who wants to explore and analyze data effectively.
With Python as your ally, the process of statistical data exploration becomes accessible and powerful. With a series of articles, we will delve further into these techniques, exploring how Python can be used in advanced ways to address complex statistical challenges. Prepare to dive into the details and gain a new perspective on data analysis with Python as your trusted guide.
Python libraries for Statistics
Statsmodels is an open-source library that offers a wide range of tools for estimating statistical models, running statistical tests, and visualizing data. Developed to provide a solid foundation for econometric and statistical analysis, this library stands out for its ability to integrate advanced models with an ease of use that makes it accessible to both beginners and industry experts.
R’s role in statistical analysis
R is an open-source programming language and development environment widely used for statistical analysis and data visualization. Its statistics-specific design offers a wide assortment of statistical packages and tools that facilitate data manipulation and transformation. Thanks to the ability to write code, R allows you to automate analyses, simplifying the management of complex data through structures such as data frames.
The Two Pillars
Descriptive Statistics and Inferential Statistics
Descriptive Statistics
Descriptive Statistics, aims to outline and summarize the data. Through centrality measures such as mean, median and mode, it searches for the beating heart of a data set, revealing its most obvious characteristics. Measures of dispersion, such as standard deviation and IQR, delineate the breadth of the distribution and its variability.
Inferential Statistics
Inferential Statistics embarks on a bolder journey. Through Hypothesis Testing, try to make bold statements about the population based on a representative sample. Probability distributions, such as normal and Student’s t, serve as tools to quantify the degree of uncertainty in our conclusions.
Descriptive Statistics Vs Inferential Statistics
Descriptive Statistics offers an immediate and tangible overview of the data. With clear graphs and measurements, it paints a detailed portrait of the numerical behavior of a set of observations. On the other hand, Inferential Statistics goes further, trying to generalize these observations beyond the sample itself.
The Other two Souls of Statistics
In addition to the two giants, the statistic also boasts other souls.
Bayesian Statistics
Bayesian Statistics is based on Bayes’ theorem, incorporating a priori information to improve estimates. This perspective, different from the Frequentist one of Inferential Statistics, offers an alternative way of interpreting and using data.
Nonparametric Statistics
Nonparametric Statistics embraces the idea of not making specific assumptions about the shape of the underlying distribution. Tests such as the Wilcoxon test or the Kruskal-Wallis test apply when the conditions for parametric tests are not met.
The Allure of the Unknown: The Continuous Evolution of Statistics
Statistics, in all its charm, is destined to evolve. The modern era sees the emergence of machine learning techniques, which integrate advanced statistical approaches to emerge complex patterns from data. This fusion of disciplines promises to bring statistics to face more complex challenges, guiding us through the ever-growing labyrinth of digital data.
In conclusion, the fundamentals of statistics are an intrinsic link in understanding and interpreting our data-driven world. Descriptive Statistics paints the picture, Inferential Statistics guides us on our journey. With the addition of perspectives such as Bayesian Statistics and Non-Parametric Statistics, our conceptual arsenal is enriched, preparing us to face the challenges of the future and unravel new mysteries through numerical analysis.