



Il Deep learning è una tecnica computazionale che permette di estrarre e trasformare i dati da fonti come, per esempio, il parlare umano o la classificazione di immagini, usando strati multipli di reti neurali. Ciascuno di questi strati prende i suoi input dagli strati precedenti e li rifinisce, così in maniera progressiva. Gli strati vengono addestrati da algoritmi che minimizzano i loro errori e migliorano la loro accuratezza. In questo modo le reti imparano ad effettuare dei compiti specifici.
[wpda_org_chart tree_id=46 theme_id=50]
Gli ambiti di applicazione
Il Deep learning è uno strumento potente, flessibile e soprattutto semplice. Questo è il motivo per cui viene applicato in moltissime discipline. Queste includono sia le scienze fisiche che sociali, o la medicina, la finanza, la ricerca scientifica e altro ancora.
Ecco un elenco di alcune discipline che usano il deep learning:
- Natural Language Processing (NLP). Il deep learning si è dimostrato in grado di riconoscere le parole pronunciate (speech recognition) ed inoltre è particolarmente efficace nel trattamento della documentazione scritta. E’ infatti in grado di ricercare dei nomi, concetti e dati all’interno di migliaria di articoli e documenti vari.
- Computer vision. Il deep learning ha posto le fondamenta per l’interpretazione delle immagini, in particolare nel riconoscimento facciale, e nella risoluzione di problemi come la localizzazione di veicoli e pedoni dalle immagini delle webcam.
- Medicina. Il deep learning è in grado di analizzare le immagini di diagnostica ed apprendere il riconoscimento di eventuali anomalie. Inoltre può apprendere da caratteristiche fisiologiche la scoperta di patologie.
- Biologia. Il deep learning sta tornando molto utile nella classificazione delle proteine, nella genomica, nella classificazione delle cellule, e nelle analisi delle interazioni proteina-proteina
- Generazioni di immagini: Il deep learning è in grado di modificare le immagini in modo intelligente, con operazioni complesse come la colorazione di immagini in bianco e nero, nell’incremento di risoluzione delle immagini, nella rimozione del rumore dalle immagini, e nel saper comporre opere artistiche utilizzando gli stili di artisti famosi partendo da immagini base.
- Ricerca Web: i motori di ricerca su web fanno uso del deep learning.
- Giochi: sempre più giochi fanno uso di intelligenza artificiale, per migliorare la strategia ed simulare il comportamento umano in avversari artificiali.
- Robotica: Il deep learning sta trovando applicazioni nel calcolo delle traiettorie e della dinamica di sistemi robotici complessi per manipolazione di oggetti.
Alla base del deep learning: le reti neurali
Alla base del Deep Learning vi sono le reti neurali. Sebbene siano state ideate nell’immediato dopoguerra, sono passati parecchi decenni prima che le reti neurali potessero essere considerate in qualche modo utili. Infatti per parecchio tempo furono trascurate poiché viste come un semplice modello matematico. Le reti neurali assunsero un valore pratico solo recentemente, grazie al potenziamento progressivo dei calcolatori e l’avanzamento della tecnologia informatica.
Inoltre il modello artificiale di un neurone singolo (perceptrone) non è in grado di evidenziare delle forme di apprendimento. Cosa che invece è siamo in grado di fare quando si usano diversi strati di neuroni, collegati in determinati modi tra di loro. Questi modelli complessi e strutturati, sono le reti neurali.
Il passaggio da un modello a singolo perceptrone, ad una loro rete di interconnessioni a strati con determinate soglie e addizioni di segnali, ha richiesto oltre 30 anni di studi. Uno sviluppo favorito solo nella loro capacità di realizzazione grazie all’avanzamento delle capacità di calcolo dei nuovi processori. E dalle reti neurali ecco nascere il Deep Learning, divenuto oggi una vera e propria disciplina scientifica.
Le reti neurali vengono spesso comparate al cervello umano proprio per il loro particolare modo di funzionare. Queste operano, infatti, come sistemi paralleli non lineari di processamento dell’informazione che eseguono in maniera rapida calcoli come:
- pattern recognition
- pattern perception
Come risultato, le reti neurali si applicano a campi come
- speech recognition
- audio recognition
- image recognition
dove le forme di input ed i segnali sono completamente non lineari.
La storia delle Reti Neurali
La prima intuizione alla possibilità di creare un modello di neurone risale al 1943, e si deve a Warren McCulloch, un neurofisiologo, e Walter Pitts, un logico, Entrambe lavorarono allo sviluppo di un modello matematico di neurone artificiale. Basandosi sugli studi del funzionamento dei neuroni reali, intuirono che il modello potesse essere realizzato utilizzando semplici addizioni e soglie.

Dal punto di vista pratico, si può invece affermare che il vero padre del neurone artificiale fu Rosenblatt. Infatti sviluppò nel 1957, basandosi sul modello matematico di McCulloch e Pitts, un dispositivo, il Mark I Perceptron. Nel suo famoso articolo The Design of an Intelligent Automaton Rosenblatt scrisse: “We are now about to witness the birth of such a machine–-a machine capable of perceiving, recognizing and identifying its surroundings without any human training or control.”


Il perceptrone che realizzò Rosenblatt era in grado di riconoscere con successo figure semplici. Poco dopo, Marvin Minsky, un professore del MIT, nel suo libro Perceptrons (MIT Press), espose vari studi su questi oggetti, dimostrando che un singolo strato di perceptroni non era in gradi apprendere funzioni matematiche semplici, cosa che invece erano in grado di fare strati multipli (reti neurali).
Purtroppo la comunità accademica globale, non fu minimamente impressionata da tale scoperta, rimanendo disinteressata all’argomento in generale e lasciandolo nel limbo per oltre 30 anni.
Fu solo con l’avvento dell’informatica e dei nuovi calcolatori che negli anni 80 e 90 si ripresero gli studi di Minsky per la realizzazione di progetti reali e pratici. Purtroppo anche in quegli anni, la tecnologia portò allo sviluppo di reti neurali a più strati (che erano in grado di svolgere lavori utili) troppo lente e grandi da avere un risvolto pratico.
Da allora sono passati altri 30 anni e ad ogni progresso nella tecnologia informatica e nella potenza di calcolo, ha portato ad un evidente miglioramento delle reti neurali, con la conseguente realizzazione di progetti pratici. Ed è così che si è sviluppato il Deep Learning. Ora finalmente abbiamo quello che aveva al tempo promesso Rosenblatt: “a machine capable of perceiving, recognizing, and identifying its surroundings without any human training or control.”
Il Single Layer Perceptron (SLP)
Il Single Layer Perceptron (SLP), o perceptron a singolo strato, è un tipo di rete neurale artificiale che costituisce il fondamento dei modelli più complessi di Deep Learning. Tuttavia, va notato che il termine “deep” in deep learning si riferisce a reti neurali profonde con più di uno strato nascosto, mentre il perceptron a singolo strato è considerato un modello di apprendimento superficiale.

Il SLP è composto da un solo strato di nodi, anche chiamati perceptron o neuroni, che ricevono input pesati, li sommano e applicano una funzione di attivazione per produrre l’output. La struttura base di un perceptron è la seguente:
Input: Gli input vengono moltiplicati per i pesi associati e sommati.


Funzione di attivazione: La somma ponderata viene poi passata attraverso una funzione di attivazione per produrre l’output del perceptron.


La funzione di attivazione introduce non linearità nella rete, consentendo al perceptron di apprendere relazioni complesse tra gli input e gli output.


ARTICOLO DI APPROFONDIMENTO
Il SLP è in grado di apprendere solo modelli lineari e risolvere problemi di classificazione binaria, dove l’output è 0 o 1. Tuttavia, la sua limitazione principale è che non può affrontare problemi che richiedono la modellazione di relazioni non lineari complesse. Per superare queste limitazioni, sono stati sviluppati modelli più complessi come i Multi-Layer Perceptron (MLP), che consistono in più strati nascosti di perceptron, permettendo alla rete di apprendere rappresentazioni più complesse e di affrontare problemi più difficili.
Dalle reti neurali al Deep Learning: i Multi-Layer Perceptron (MLP)
Dalle reti neurali artificiali al Deep Learning vi è un passaggio fondamentale. Singoli neuroni artificiali connessi insieme per diventare una rete neurale non fanno il Deep Learning. Infatti, non tutte le reti neurali artificiali sono in grado di effettuare il Deep Learning. Le reti devono essere “Deep” cioè devono essere strutturate con molti strati nascosti (hidden layer), e non tutte le architetture di deep learning sono delle reti neurali.

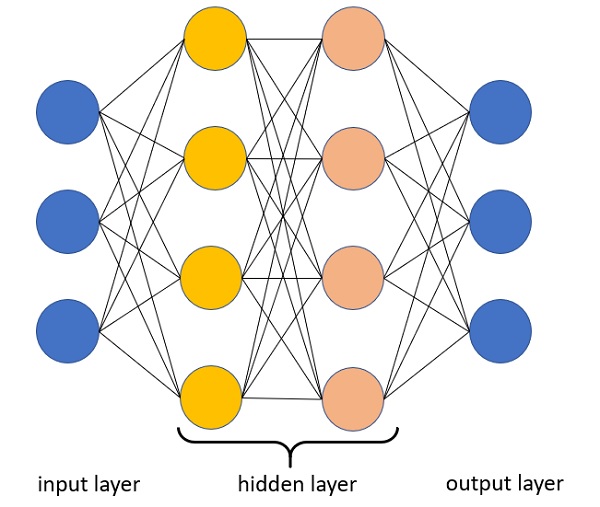
Infatti il Deep Learning sfrutta i diversi strati di reti neurali per effettuare livelli multipli di rappresentazione e astrazione passando di strato in strato.
A ciascun strato o livello di rete neurale corrisponde un livello distinto di concetti, dove concetti di livello più alto vengono definiti dai livelli inferiori, per essere elaborati e convertiti a concetti via via sempre più astratti negli strati superiori.
Si tratta quindi di un insieme di algoritmi che utilizza le reti neurali artificiali per imparare a scomporre dati complessi come immagini, suoni e testo in diversi livelli di astrazione.
Le architetture del Deep Learning
Una delle grandi potenzialità delle reti neurali è che possono essere strutturate in infiniti modi. Negli ultimi anni si sono sviluppate tantissime tipologie di interconnessioni tra neuroni artificiali, chiamate architetture. Ognuna di esse è stata studiata e presenta caratteristiche peculiari di apprendimento che le rendono specifiche per determinate applicazioni.
Eccone alcuni esempi:
- Deep Neural Networks
- Deep Belief Networks
- Convolutional Neural Networks
- Convolutional Deep Belief Networks
- Deep Boltzmann Machines
- Stacked Auto Encoders
- Deep Stacking Networks
- Tensor Deep Stacking Networks (T-DSN)
- Spike-and-Slab RBMs
- Compoung Hierarchical-Deep Models
- Deep Coding Networks and Deep Kernel Machines
I Software per il Deep Learning
Uno degli aspetti fondamentali per lo sviluppo ed il successo del Deep Learning in questi ultimi 10 anni è il fatto che esistono nuovissime applicazioni in grado di fornire tutti gli strumenti necessari per mettere in piedi architetture di reti neurali e studiarle.
Eccone alcuni tra quelli disponibili attualmente.
- Neural Designer
- H2O.ai
- DeepLearningKit
- Microsoft Cognitive Toolkit
- Keras
- ConvNetJS
- Torch
- Deeplearning4j
- Gensim
- Apache SINGA
- Caffe
- Theano
- ND4J
- MXNet