
L’algoritmo Gradient Boosting è una tecnica di apprendimento automatico che si basa sulla creazione sequenziale di modelli deboli, spesso alberi decisionali, per creare un modello più forte in grado di affrontare problemi di regressione e classificazione. L’obiettivo principale del Gradient Boosting è ridurre l’errore del modello combinando i punti deboli dei modelli individuali.
[wpda_org_chart tree_id=21 theme_id=50]
L’Algoritmo Gradient Boosting
Ecco come funziona l’algoritmo Gradient Boosting in generale:
- Inizializzazione del modello: Si inizia con un modello semplice, noto come “modello base” o “modello debolmente appreso”. Nei problemi di regressione, questo potrebbe essere un singolo valore costante (ad esempio, la media dei target nel set di addestramento). Nei problemi di classificazione binaria, potrebbe essere la log-odds di probabilità di classe.
- Calcolo del residuo: Si calcolano i residui tra le previsioni del modello attuale e i valori target veri. Questi residui rappresentano l’errore rimanente nel modello.
- Creazione del nuovo modello debolmente appreso: Un nuovo modello debolmente appreso viene addestrato per predire i residui calcolati nel passo precedente. Questo modello cercherà di catturare i “mancanti” nella previsione del modello precedente.
- Aggiornamento del modello combinato: Le previsioni del nuovo modello vengono moltiplicate per un tasso di apprendimento (learning rate) e quindi aggiunte alle previsioni del modello precedente. Questo passaggio permette di aggiornare il modello combinato per avvicinarsi alle previsioni corrette.
- Iterazioni: I passaggi 2-4 vengono ripetuti per un certo numero di iterazioni o fino a quando l’errore non diminuisce significativamente.
- Modello finale: Il modello finale è una combinazione pesata di tutti i modelli debolmente appresi. Questi modelli deboli sono stati addestrati in modo che i residui della previsione di ogni modello vengano corretti dai modelli successivi.
L’idea chiave del Gradient Boosting è che ogni nuovo modello debolmente appreso si concentra sugli errori commessi dai modelli precedenti. Il processo di combinazione di questi modelli deboli migliora progressivamente le prestazioni del modello complessivo.
In Python, puoi utilizzare librerie come scikit-learn, XGBoost, LightGBM e CatBoost per implementare l’algoritmo Gradient Boosting. Queste librerie offrono implementazioni ottimizzate e consentono di personalizzare diversi parametri per adattare il modello alle tue esigenze specifiche.
Un po’ di Storia
Gradient Boosting è una tecnica di apprendimento automatico che si basa sulla combinazione di modelli deboli (spesso alberi decisionali) in un modo sequenziale per creare un modello più forte. È una delle tecniche più potenti ed efficaci per la regressione e la classificazione. Ecco una panoramica della storia del Gradient Boosting:
Anni ’90: L’idea di boosting (potenziamento) è stata introdotta da Robert Schapire nel 1990. Ha sviluppato l’algoritmo “Adaptive Boosting” (AdaBoost), che è stato uno dei primi algoritmi di boosting. AdaBoost si concentra su problemi di classificazione e crea un modello forte combinando modelli deboli, ognuno dei quali viene addestrato in modo iterativo per focalizzarsi sugli esempi difficili.
Fine anni ’90 – Inizio anni 2000: Nel corso degli anni ’90 e nei primi anni 2000, l’approccio di boosting è stato ulteriormente sviluppato e migliorato. Nel 2001, Jerome Friedman ha introdotto l’algoritmo Gradient Boosting Machine (GBM), che ha esteso il concetto di boosting anche a problemi di regressione. L’approccio di GBM si basa sull’ottimizzazione della funzione di perdita attraverso gradient descent.
Anni 2000: L’idea di Gradient Boosting ha continuato a evolversi con l’introduzione di varianti e miglioramenti. Nel 2003, Jerome Friedman, Trevor Hastie e Robert Tibshirani hanno sviluppato l’algoritmo “Gradient Boosting Regression Trees” (GBRT), che utilizza alberi decisionali deboli come modelli base. Questo ha reso l’approccio ancora più potente e flessibile.
Anni successivi: Nel corso degli anni successivi, altre varianti e implementazioni del Gradient Boosting sono state sviluppate. Ad esempio, nel 2006 è stato introdotto XGBoost (eXtreme Gradient Boosting), che ha migliorato ulteriormente le prestazioni e la velocità di esecuzione dell’approccio. Successivamente, sono stati sviluppati altri framework e librerie come LightGBM e CatBoost, che offrono prestazioni ancora migliori e nuove funzionalità.
Oggi, Gradient Boosting e le sue varianti sono ampiamente utilizzati nell’apprendimento automatico e nella pratica del data science. Queste tecniche sono apprezzate per la loro capacità di gestire dati complessi, ridurre l’overfitting, migliorare la generalizzazione e ottenere previsioni accurate su una vasta gamma di problemi di regressione e classificazione.

Se vuoi approfondire l’argomento e scoprire di più sul mondo della Data Science con Python, ti consiglio di leggere il mio libro:
Fabio Nelli
Il Gradient Boosting con la libreria scikit-learn
In Python, puoi utilizzare la libreria scikit-learn per implementare l’algoritmo Gradient Boosting e creare modelli basati su di esso. Questo algoritmo può essere utilizzato per due diversi approcci del Machine Learning.
- Classificazione
- Regressione
La Classificazione con Gradient Boosting
Ecco un esempio di come puoi utilizzare scikit-learn per creare e addestrare un modello di Classification Gradient Boosting utilizzando il dataset Breast Cancer Wisconsin:
Step 1: Importa le librerie necessarie
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_scoreIn questa sezione, stiamo importando le librerie necessarie per creare e addestrare il modello di Classification Gradient Boosting.
Step 2: Carica il dataset e dividi i dati
# Carica il dataset Breast Cancer Wisconsin come esempio
breast_cancer = load_breast_cancer()
X = breast_cancer.data
y = breast_cancer.target
# Dividi il dataset in set di addestramento e di test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Qui stiamo caricando il dataset Breast Cancer Wisconsin utilizzando la funzione load_breast_cancer() e dividendo i dati in set di addestramento e di test utilizzando la funzione train_test_split().
Step 3: Crea e addestra il modello Gradient Boosting
# Crea il modello Gradient Boosting Classifier
clf = GradientBoostingClassifier(random_state=42)
# Addestra il modello sul set di addestramento
clf.fit(X_train, y_train)In questo step, stiamo creando un oggetto GradientBoostingClassifier e lo addestriamo sul set di addestramento utilizzando il metodo fit().
Step 4: Effettua previsioni e calcola l’accuratezza
# Effettua previsioni sul set di test
predictions = clf.predict(X_test)
# Calcola l'accuratezza delle previsioni
accuracy = accuracy_score(y_test, predictions)
print("Accuracy:", accuracy)In questo passaggio, stiamo effettuando previsioni sul set di test utilizzando il metodo predict() del modello addestrato e quindi calcoliamo l’accuratezza delle previsioni utilizzando la funzione accuracy_score(). Eseguendo si ottiene il valore dell’accuratezza.
Accuracy: 0.956140350877193Si possono utilizzare delle visualizzazioni che permettono di comprendere meglio la validità o meno del modello appena utilizzato.
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, confusion_matrix
import seaborn as sns
# Effettua previsioni delle probabilità sul set di test
probabilities = clf.predict_proba(X_test)[:, 1]
# Calcola la curva ROC
fpr, tpr, thresholds = roc_curve(y_test, probabilities)
roc_auc = auc(fpr, tpr)
# Visualizza la curva ROC
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = {:.2f})'.format(roc_auc))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Curva ROC del Gradient Boosting Classifier')
plt.legend(loc='lower right')
plt.show()
# Visualizza la matrice di confusione
cm = confusion_matrix(y_test, predictions)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues', xticklabels=breast_cancer.target_names, yticklabels=breast_cancer.target_names)
plt.xlabel('Previsioni')
plt.ylabel('Valori Veri')
plt.title('Matrice di Confusione del Gradient Boosting Classifier')
plt.show()
# Visualizza l'importanza delle feature
feature_importances = clf.feature_importances_
feature_names = breast_cancer.feature_names
plt.barh(range(len(feature_importances)), feature_importances, align='center')
plt.yticks(range(len(feature_names)), feature_names)
plt.xlabel('Importanza delle Feature')
plt.title('Importanza delle Feature nel Gradient Boosting Classifier')
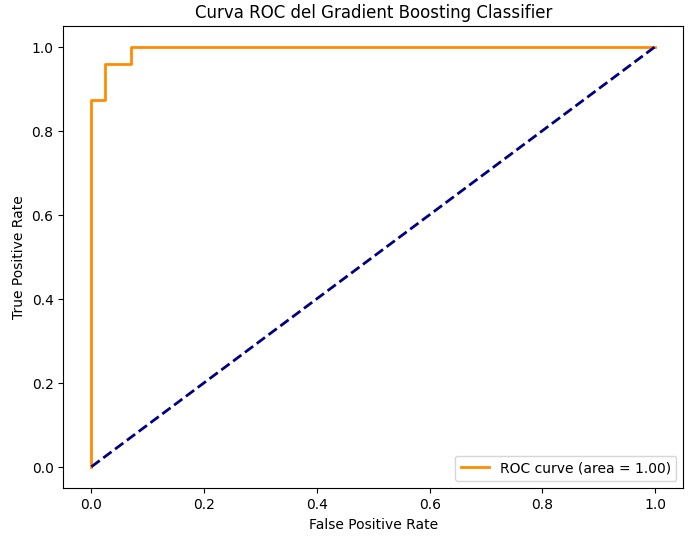
plt.show()Il codice appena inserito, se eseguito, produrrà tre diverse tipologie di visualizzazioni. La prima visualizzazione è una Curva ROC: Una rappresentazione grafica delle prestazioni del classificatore, mostrando il tasso di falsi positivi rispetto al tasso di veri positivi al variare della soglia di decisione.
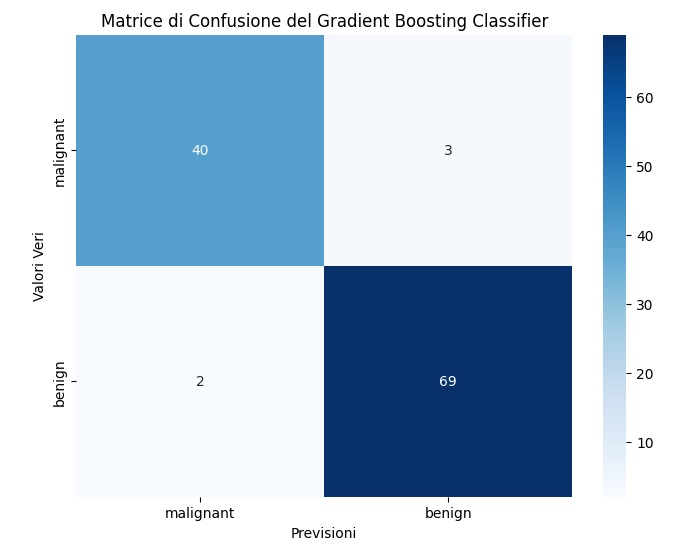
Matrice di Confusione: Un grafico a matrice che mostra il numero di predizioni corrette e errate per ciascuna classe. Questo può aiutarti a comprendere meglio le prestazioni del tuo modello.
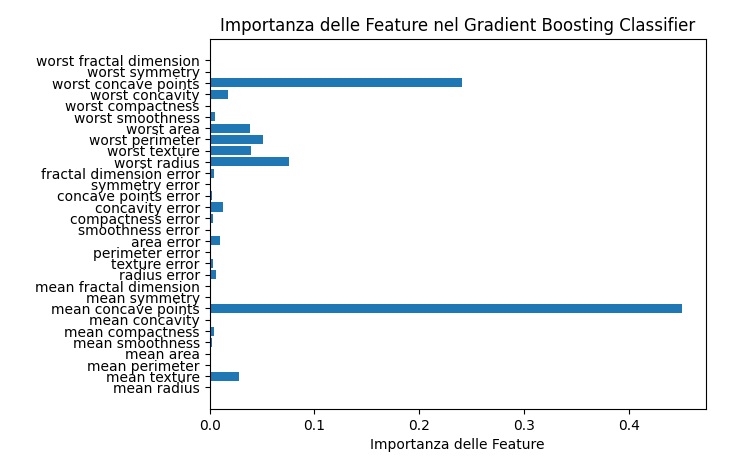
Importanza delle Feature: Un grafico a barre orizzontale che mostra l’importanza relativa di ciascuna feature nel modello Gradient Boosting Classifier.
Questi step combinati formano un esempio completo di come utilizzare scikit-learn per creare e addestrare un modello di Classification Gradient Boosting per un problema di classificazione. Puoi personalizzare ulteriormente il modello utilizzando gli iperparametri del Gradient Boosting Classifier per adattarlo alle tue esigenze.

Libro Suggerito
Se sei interessato al Machine Learning e ti piace programmare in Python ti suggerisco di leggere questo libro:
La Regressione con il Gradient Boosting
Ecco un esempio di come puoi utilizzare scikit-learn per creare e addestrare un modello di Regression Gradient Boosting utilizzando il dataset Diabetes:
Step 1: Importa le librerie necessarie
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_errorIn questa sezione, stiamo importando le librerie necessarie per creare e addestrare il modello di Regression Gradient Boosting.
Step 2: Carica il dataset e dividi i dati
# Carica il dataset Diabetes come esempio
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
# Dividi il dataset in set di addestramento e di test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Qui stiamo caricando il dataset Diabetes utilizzando la funzione load_diabetes() e dividendo i dati in set di addestramento e di test utilizzando la funzione train_test_split().
Step 3: Crea e addestra il modello Regression Gradient Boosting
# Crea il modello Regression Gradient Boosting
reg = GradientBoostingRegressor(random_state=42)
# Addestra il modello sul set di addestramento
reg.fit(X_train, y_train)In questo step, stiamo creando un oggetto GradientBoostingRegressor e lo addestriamo sul set di addestramento utilizzando il metodo fit().
Step 4: Effettua previsioni e calcola l’errore medio quadratico
# Effettua previsioni sul set di test
predictions = reg.predict(X_test)
# Calcola l'errore medio quadratico delle previsioni
mse = mean_squared_error(y_test, predictions)
print("Mean Squared Error:", mse)In questo passaggio, stiamo effettuando previsioni sul set di test utilizzando il metodo predict() del modello addestrato e quindi calcoliamo l’errore medio quadratico delle previsioni utilizzando la funzione mean_squared_error(). Eseguendo si ottiene il seguente valore di MSE.
Mean Squared Error: 2898.4366729135227Anche in questo caso di regressione del Gradient Boosting è possibile fornire delle visualizzazioni da cui sia possibile valutare la validità di un modello appena sviluppato.
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Carica il dataset Diabetes come esempio
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
# Dividi il dataset in set di addestramento e di test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Crea il modello Regression Gradient Boosting
reg = GradientBoostingRegressor(random_state=42)
# Addestra il modello sul set di addestramento
reg.fit(X_train, y_train)
# Effettua previsioni sul set di test
predictions = reg.predict(X_test)
# Visualizza il grafico di dispersione tra valori effettivi e previsti
plt.scatter(y_test, predictions)
plt.xlabel('Valori Effettivi')
plt.ylabel('Previsioni')
plt.title('Confronto tra Valori Effettivi e Previsioni')
plt.show()
# Visualizza l'importanza delle feature
feature_importances = reg.feature_importances_
feature_names = diabetes.feature_names
plt.barh(range(len(feature_importances)), feature_importances, align='center')
plt.yticks(np.arange(len(feature_names)), feature_names)
plt.xlabel('Importanza delle Feature')
plt.title('Importanza delle Feature nel Gradient Boosting Regressor')
plt.show()
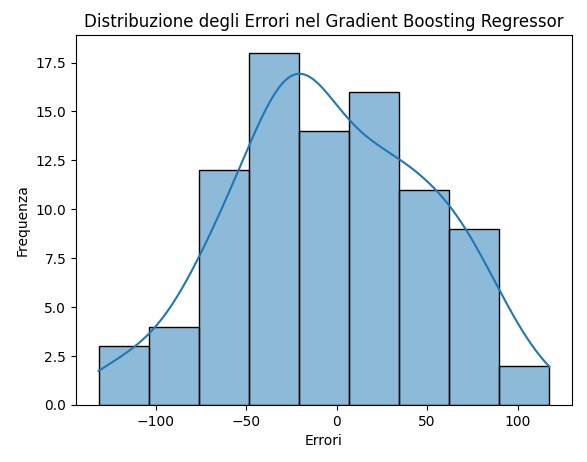
# Visualizza la distribuzione degli errori
errors = y_test - predictions
sns.histplot(errors, kde=True)
plt.xlabel('Errori')
plt.ylabel('Frequenza')
plt.title('Distribuzione degli Errori nel Gradient Boosting Regressor')
plt.show()
Eseguendo questo codice si otterranno tre diversi tipi di visualizzazione. La prima visualizzazione è un Grafico di Dispersione. Un grafico di dispersione che mostra la relazione tra i valori effettivi e le previsioni del modello. Idealmente, i punti dovrebbero allinearsi con la linea diagonale, indicando una buona previsione.
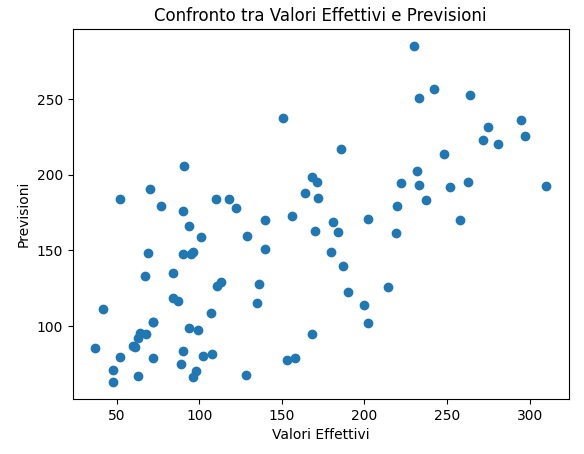
La seconda visualizzazione rappresenta l’Importanza delle Feature, si tratta di un grafico a barre orizzontale che mostra l’importanza relativa di ciascuna feature nel modello Gradient Boosting Regressor.

L’ultima visualizzazione è la distribuzione degli Errori: un istogramma che mostra la distribuzione degli errori, aiutandoti a comprendere la precisione del modello nelle diverse predizioni.
Questi step combinati formano un esempio completo di come utilizzare scikit-learn per creare e addestrare un modello di Regression Gradient Boosting per un problema di regressione. Puoi personalizzare ulteriormente il modello utilizzando gli iperparametri del Gradient Boosting Regressor per adattarlo alle tue esigenze.
Alcuni dataset per esercitarsi nei problemi di classificazione con scikit-learn
Se si vuole fare un po’ di pratica di Machine Learning lavorando con problemi di classificazione esistono dei dataset già pronti su cui esercitarsi. Ecco alcuni dataset che puoi utilizzare per esempi pratici con la Classification Gradient Boosting utilizzando scikit-learn senza utilizzare il dataset Iris:
- Breast Cancer Wisconsin (Diagnostic) Dataset: Questo dataset contiene caratteristiche estratte da immagini di aspirati sottili di noduli al seno e l’obiettivo è classificare se un tumore è benigno o maligno.
- Carica il dataset:
from sklearn.datasets import load_breast_cancer
- Carica il dataset:
- Wine Dataset: Questo dataset contiene misurazioni chimiche di vini provenienti da tre diverse varietà. L’obiettivo è classificare la varietà del vino.
- Carica il dataset:
from sklearn.datasets import load_wine
- Carica il dataset:
- Digits Dataset: Questo dataset contiene immagini di cifre scritte a mano e l’obiettivo è classificare quale cifra è rappresentata.
- Carica il dataset:
from sklearn.datasets import load_digits
- Carica il dataset:
- Heart Disease UCI Dataset: Questo dataset contiene informazioni cliniche per pazienti e l’obiettivo è classificare se un paziente ha o non ha una malattia cardiaca.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
- Bank Marketing Dataset: Questo dataset contiene informazioni su campagne di marketing bancario e l’obiettivo è classificare se un cliente sottoscriverà o meno un deposito a termine.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
- Titanic Dataset: Questo dataset contiene informazioni sui passeggeri del Titanic e l’obiettivo è classificare se un passeggero sopravvivrà o meno.
- Carica il dataset: Puoi scaricare il dataset da Kaggle
Per utilizzare uno di questi dataset, puoi importare il dataset appropriato utilizzando la funzione load_* fornita da sklearn.datasets. Assicurati di leggere la documentazione associata al dataset per capire le caratteristiche, la variabile di output e come preparare i dati per l’addestramento del modello Gradient Boosting.
Alcuni dataset per esercitarsi nei problemi di regressione con scikit-learn
Ecco alcuni dataset che puoi utilizzare per esempi pratici con la Regression Gradient Boosting utilizzando scikit-learn:
- Boston Housing Dataset: Questo dataset contiene dati sulle abitazioni nella zona di Boston e l’obiettivo è prevedere il valore mediano delle abitazioni.
- Carica il dataset:
from sklearn.datasets import load_boston
- Carica il dataset:
- Diabetes Dataset: Questo dataset contiene misurazioni mediche correlate al diabete e l’obiettivo è prevedere la progressione della malattia un anno dopo.
- Carica il dataset:
from sklearn.datasets import load_diabetes
- Carica il dataset:
- California Housing Dataset: Questo dataset contiene dati immobiliari in California e l’obiettivo è prevedere il valore mediano delle abitazioni in diverse aree.
- Carica il dataset: Puoi scaricare il dataset da scikit-learn datasets
- Energy Efficiency Dataset: Questo dataset contiene informazioni sulla prestazione energetica degli edifici e l’obiettivo è prevedere l’efficienza energetica.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
- Concrete Compressive Strength Dataset: Questo dataset contiene dati sulla resistenza alla compressione del calcestruzzo e l’obiettivo è prevedere la resistenza alla compressione.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
- Combined Cycle Power Plant Dataset: Questo dataset contiene dati sulla produzione di energia in una centrale elettrica e l’obiettivo è prevedere l’efficienza energetica.
- Carica il dataset: Puoi scaricare il dataset da UCI Machine Learning Repository
Per utilizzare uno di questi dataset, puoi importare il dataset appropriato utilizzando la funzione load_* fornita da sklearn.datasets. Assicurati di leggere la documentazione associata al dataset per capire le caratteristiche, la variabile di output e come preparare i dati per l’addestramento del modello Regression Gradient Boosting.